
Impossible d’extraire le texte d’un PDF dans ChatGPT ? La vraie cause et la solution en 3 étapes
Vous avez le PDF idéal : un article universitaire dense, un contrat client scanné ou un chapitre de manuel. Vous l’importez dans ChatGPT pour obtenir un résumé ou une analyse, puis tout se bloque : « Aucun texte n’a pu être extrait de ce fichier. » C’est un problème très courant, et particulièrement frustrant quand il casse votre flux de travail. Si vous voyez ce message d’erreur, vous n’êtes pas seul — et le souci ne vient pas de vous, mais d’une limite fondamentale de ce que ChatGPT sait faire.

Le vrai problème, c’est que ChatGPT est un modèle de langage, pas un convertisseur de documents universel. Il est très efficace pour traiter du texte numérique propre. En revanche, beaucoup de PDF — surtout les scans et les rapports complexes — sont en réalité des images de texte, et non du texte exploitable. ChatGPT n’intègre pas nativement la reconnaissance optique de caractères (OCR) nécessaire pour « lire » ces documents basés sur des images. C’est un peu comme demander à un excellent linguiste, incapable de voir, de décrire la photo d’une page de livre. Dans ce guide, nous allons expliquer clairement pourquoi cette erreur apparaît et vous montrer une méthode fiable en trois étapes pour récupérer le texte dont vous avez besoin.
Verdict rapide : ChatGPT ou un extracteur de texte PDF avec OCR ?
Si vous êtes pressé, voici l’essentiel. La bonne méthode pour extraire le texte d’un PDF dépend entièrement du type de PDF que vous avez. S’agit-il d’un document texte classique, ou d’un PDF scanné plus difficile à traiter ?
Ce tableau vous aide à choisir entre les capacités natives de ChatGPT et un outil conçu spécialement pour l’OCR PDF.
| Fonction / scénario | ChatGPT (import natif) | Extracteur OCR dédié (ex. Lynote) |
|---|---|---|
| PDF scanné / PDF image | Échec (note : 1/5) | Excellent (note : 5/5) |
| Mises en page sur plusieurs colonnes | Résultat aléatoire ; le texte est souvent mélangé | Bon ; préserve l’ordre de lecture |
| Fichiers protégés par mot de passe | Échec (note : 1/5) | Échec (par conception, pour des raisons de sécurité) |
| Vitesse (pour les PDF propres) | Rapide pour les fichiers courts et simples | Rapide ; optimisé pour les gros volumes |
| Cas d’usage idéal | Analyser des PDF simples créés numériquement (ex. documents exportés depuis Microsoft Word) | Extraire le texte de scans, de photos de documents ou de mises en page complexes |
Ces notes sont des estimations éditoriales (1 = faible, 5 = excellent), pas des benchmarks mesurés.
À retenir : si votre PDF a été créé directement depuis un éditeur de texte comme Microsoft Word ou Google Docs, ChatGPT peut parfois s’en sortir. Pour tout le reste — surtout les documents scannés, photographiés ou très mis en forme — il vous faut un outil doté d’un moteur OCR dédié.
Les 4 principales raisons pour lesquelles ChatGPT ne lit pas votre PDF
Vous vous demandez peut-être : « Si je vois le texte à l’écran, pourquoi ChatGPT n’y arrive pas ? » La réponse tient à la façon dont les PDF sont construits. Un PDF n’est pas toujours ce qu’il semble être. Voici les quatre causes les plus fréquentes derrière cette erreur d’extraction.
1. PDF image ou PDF scanné (la cause n°1)
C’est de loin la raison la plus fréquente. Quand vous scannez un document papier ou enregistrez un fichier sous forme de « PDF image », vous n’enregistrez pas du texte. Vous enregistrez une photo de la page. Pour un ordinateur, les lettres dans ce fichier ne sont pas différentes des pixels d’une image d’arbre.
- Le scénario : vous êtes étudiant et vous essayez d’analyser un article scientifique de 30 pages que votre professeur a scanné depuis un livre de bibliothèque. Vous l’importez, et ChatGPT ne voit qu’un ensemble d’images.
- Le blocage technique : sans reconnaissance optique de caractères (OCR) — un procédé qui analyse les images pour identifier les caractères et les convertir en texte numérique — ChatGPT est aveugle face au contenu. Il lui faut une « couche texte » pour lire le document, et les PDF scannés n’en ont pas.
2. Mises en page et formatages complexes
Les PDF sont excellents pour conserver une mise en page visuelle : colonnes, tableaux, en-têtes, pieds de page et images flottantes. Mais cette force devient aussi une faiblesse pour l’extraction de texte. L’analyseur intégré de ChatGPT reste basique : il s’attend à un flux de texte simple et linéaire.
- Le scénario : vous êtes analyste métier et vous travaillez sur un rapport d’étude de marché rempli de texte sur deux colonnes, de graphiques annotés et de tableaux de données. Quand ChatGPT essaie de le lire, le texte des colonnes s’entremêle et des phrases cohérentes deviennent incompréhensibles.
The company's growth in Q3 was a result of the new marketing... remarkable, reaching 5 million units... strategy that focused on social media. - Le blocage technique : l’analyseur ne sait pas distinguer une rupture de colonne d’une fin de paragraphe. Il lit le texte selon sa position sur la page, et non selon sa logique de lecture, ce qui produit un résultat confus.
3. Fichiers protégés par mot de passe ou chiffrés
Ici, c’est plus simple. Si un PDF nécessite un mot de passe pour être ouvert ou impose des restrictions sur la copie du texte, ChatGPT respecte ces paramètres de sécurité. Il ne va pas — et ne peut pas — les contourner.
- Le scénario : un collègue vous envoie par e-mail un rapport financier sensible protégé par mot de passe pour analyse. Vous ne pouvez pas simplement l’importer en espérant que ChatGPT l’ouvre.
- Le blocage technique : le contenu du fichier est chiffré. Tant qu’il n’est pas déverrouillé avec le bon mot de passe, les données restent illisibles pour n’importe quelle application, y compris les modèles d’IA.
4. Fichier corrompu ou encodage non standard
C’est plus rare, mais cela arrive. Le fichier PDF lui-même peut être endommagé ou utiliser un encodage de texte inhabituel que l’analyseur de ChatGPT ne reconnaît pas. Cela peut se produire après un mauvais téléchargement, une conversion défectueuse ou avec des documents très anciens. La couche texte peut techniquement exister, mais être brouillée au point de devenir inutilisable.
En bref : si un outil dédié fait mieux que ChatGPT pour extraire le texte d’un PDF, c’est surtout grâce à son moteur OCR intégré, spécialement conçu pour convertir des images de texte en caractères lisibles par une machine et exploitables par une IA.
La solution : extraire le texte de n’importe quel PDF en 3 étapes
Quand ChatGPT échoue, inutile de perdre du temps à tester d’autres prompts ou à renvoyer le même fichier. Le plus efficace consiste à prétraiter le PDF avec un outil conçu pour extraire le texte d’un PDF correctement. Un outil de transcription et d’extraction de données avec un moteur OCR performant reste la solution la plus fiable.
Voici comment faire en moins d’une minute avec un outil comme Transcription IA de Lynote, gratuit pour un usage de base et utilisable sans créer de compte.
Étape 1. Importez le PDF qui pose problème
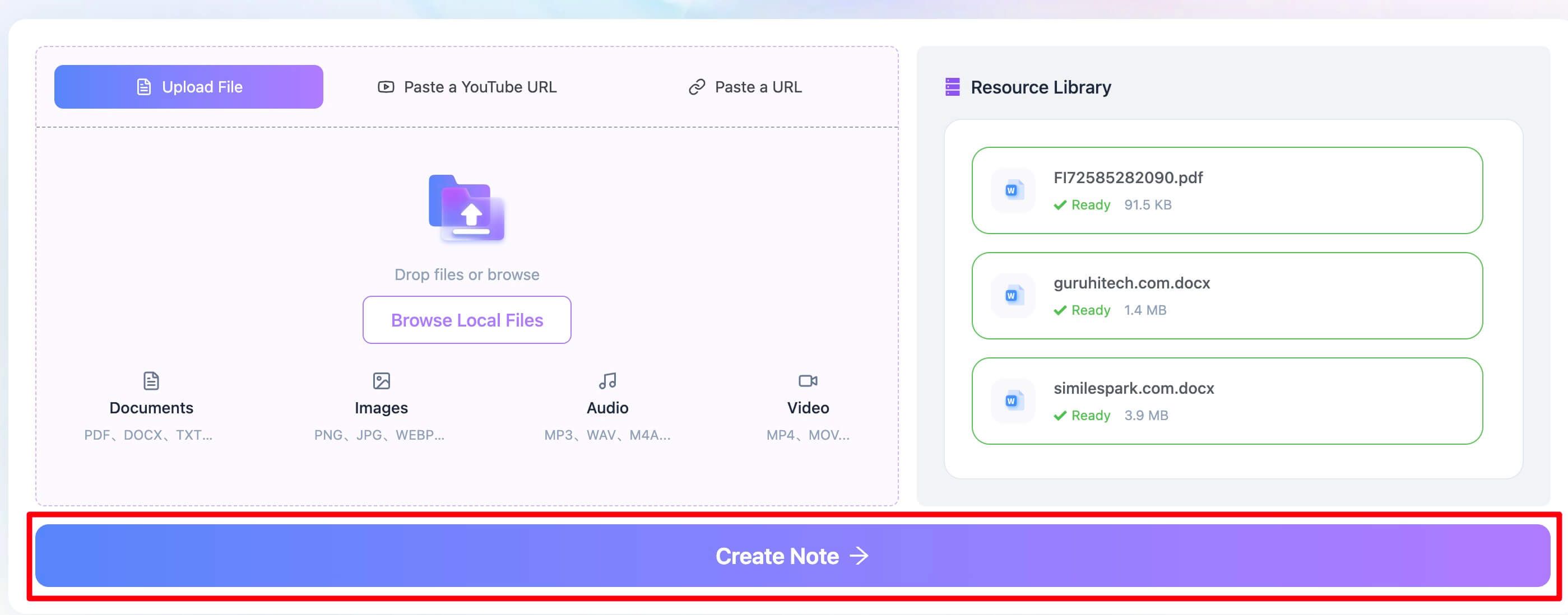
Commencez par ouvrir l’extracteur de texte PDF de Lynote. Au lieu d’envoyer votre fichier dans ChatGPT, glissez-déposez directement le PDF problématique dans la zone d’import de Lynote. Vous pouvez aussi cliquer pour parcourir votre ordinateur et sélectionner le fichier. C’est particulièrement utile pour les notes de cours scannées, les rapports complexes ou les documents en image que ChatGPT refuse immédiatement.

Étape 2. Extraire le texte du PDF
Une fois le fichier importé, cliquez simplement sur le bouton "Create Note". C’est l’étape clé. Le système de Lynote lance aussitôt le traitement avec un puissant moteur OCR. Il ne se contente pas de chercher une couche de texte existante : il analyse chaque page comme une image, reconnaît les caractères et reconstitue le texte en version numérique. L’outil prend en charge plus de 130 langues, ce qui le rend aussi efficace pour les documents internationaux.
Étape 3. Vérifiez et copiez le texte du PDF
En quelques secondes, le texte proprement extrait s’affiche dans un éditeur en ligne. Vous obtenez alors une version textuelle que ChatGPT peut comprendre facilement. Vérifiez rapidement s’il reste quelques erreurs d’OCR, faites de petites corrections si besoin, puis copiez l’ensemble du texte. Il ne vous reste plus qu’à le coller dans votre prompt ChatGPT pour lancer votre analyse, votre résumé ou votre demande. Vous pouvez aussi télécharger le texte au format .txt pour le réutiliser plus tard.

Ce processus en trois étapes fait le lien entre un PDF scanné ou en image et l’environnement textuel de ChatGPT.

Au-delà du correctif : comment choisir un bon outil pour extraire le texte d’un PDF
Dès que vous comprenez qu’il faut un outil dédié, vous découvrez vite qu’il en existe beaucoup. Alors, qu’est-ce qui distingue un excellent outil OCR PDF d’une solution moyenne ? Voici les points essentiels à vérifier, surtout si vous traitez des documents régulièrement.
- OCR haute précision : c’est indispensable. La mission principale de l’outil est de convertir un PDF scanné en texte avec précision. Un bon moteur limite les erreurs (par exemple confondre
let1, ournetm) et gère correctement différentes polices et résolutions. - Prise en charge de plusieurs langues : si vous travaillez sur des documents internationaux, des articles de recherche ou des archives, vérifiez que l’outil reconnaît bien les caractères et accents des langues dont vous avez besoin. Des outils comme Lynote, compatibles avec plus de 130 langues, offrent une vraie souplesse.
- Traitement par lot : vous cherchez à extraire le texte d’un dossier entier de factures scannées ou d’une dizaine d’articles ? Un outil capable d’importer plusieurs fichiers à la fois et de les traiter en file d’attente vous fera gagner un temps considérable par rapport à un traitement un par un.
- Options d’export flexibles : extraire le texte n’est que la première étape ; encore faut-il pouvoir l’utiliser. Recherchez des options simples en un clic pour copier dans le presse-papiers, télécharger en fichier .txt ou .docx, ou aller plus loin dans votre flux de travail. Les outils modernes peuvent aussi permettre de discuter avec le document ou de traduire le texte extrait dans la même interface.
Choisir un outil avec ces fonctionnalités transforme un blocage frustrant en étape fluide de votre travail de recherche et d’analyse.
Astuce pro : que faire si le texte extrait est brouillon ou imprécis
Même la meilleure technologie OCR n’est pas fiable à 100 %, surtout avec des scans de mauvaise qualité, des notes manuscrites ou des mises en page très complexes. Si le texte extrait est un peu désordonné, pas de panique. Voici quelques méthodes simples et efficaces pour le nettoyer rapidement.
- Corrigez les paragraphes cassés : si le texte de plusieurs colonnes a été fusionné, vous verrez de longues lignes difficiles à lire. Le plus rapide est de coller le texte dans un éditeur simple (comme le Bloc-notes ou TextEdit) puis d’appuyer manuellement sur "Entrée" pour recréer les retours de paragraphe. Cela prend une minute, mais rend le texte beaucoup plus lisible, pour vous comme pour ChatGPT.
- Utilisez Rechercher et remplacer pour les erreurs fréquentes : l’OCR fait souvent les mêmes confusions. Si vous voyez beaucoup de
1à la place del, ou des!à la place dei, utilisez la fonction "Rechercher et remplacer" de votre éditeur de texte (Ctrl+H ou Cmd+Shift+H). Quelques remplacements bien ciblés suffisent souvent à corriger 90 % des erreurs en quelques secondes. - Simplifiez avant de demander un résumé : avant d’envoyer le texte nettoyé à ChatGPT pour un résumé, pensez à supprimer les éléments inutiles comme les en-têtes, pieds de page, numéros de page et légendes de figures. Cela aide l’IA à se concentrer sur le contenu essentiel et améliore souvent la précision comme la concision du résultat.
Un petit nettoyage au départ peut vous éviter beaucoup de confusion et améliorer nettement les résultats de votre analyse par IA.
Questions fréquentes
ChatGPT-4o peut-il lire le texte d’un PDF scanné ?
Non, pas directement. Même les modèles plus avancés comme GPT-4o n’intègrent pas, dans leur fonction standard d’import de fichiers, un moteur OCR accessible à l’utilisateur. Si vous importez un PDF scanné ou un PDF image, vous obtiendrez la même erreur indiquant qu’aucun texte n’a pu être extrait. Il faut d’abord utiliser un outil OCR externe pour convertir le PDF en texte, puis coller ce texte dans votre prompt.
Pourquoi le copier-coller fonctionne depuis mon PDF, mais pas ChatGPT ?
C’est une excellente question, car elle révèle les couches invisibles d’un PDF. Beaucoup de fichiers PDF contiennent à la fois une couche image (ce que vous voyez) et une couche texte invisible (générée lors de la création du fichier). Quand vous sélectionnez puis copiez du texte, votre lecteur PDF — comme Adobe Acrobat ou Aperçu — récupère ce contenu depuis cette couche cachée. Mais si cette couche texte est corrompue, absente ou mal encodée, l’analyseur côté serveur de ChatGPT, plus limité, ne parvient pas à la lire, même si votre logiciel local y arrive.
Existe-t-il une solution gratuite pour rendre le texte de mon PDF lisible par ChatGPT ?
Oui. La méthode décrite dans cet article, avec l’offre gratuite d’un outil comme Lynote, fait partie des options gratuites les plus efficaces. Elle s’appuie sur un moteur OCR de qualité, sans paiement ni création de compte pour les extractions de base. D’autres outils OCR PDF en ligne gratuits existent, mais ils sont souvent envahis de publicités, moins précis ou très limités sur la taille des fichiers.
Pourquoi la mise en forme (gras, italique) disparaît-elle après l’extraction ?
Les outils d’extraction de texte, surtout ceux qui reposent sur l’OCR, cherchent avant tout à récupérer les caractères, pas la mise en forme enrichie. Le résultat est presque toujours du texte brut. En pratique, c’est souvent préférable pour les modèles d’IA, qui s’appuient surtout sur le sens du contenu plutôt que sur son apparence visuelle.
Conclusion : utiliser le bon outil pour extraire le texte d’un PDF
ChatGPT est un outil révolutionnaire pour travailler avec le langage, mais ce n’est pas une solution universelle pour tous les formats de fichier. L’erreur « aucun texte n’a pu être extrait de ce fichier » n’est pas un bug : elle marque simplement une limite technique. Le modèle est conçu pour traiter du texte propre et numérique, pas pour lire un PDF scanné, un PDF image ou des mises en page complexes où le texte doit d’abord être reconnu par OCR.
Pour les étudiants, les chercheurs et les professionnels qui manipulent régulièrement des documents variés, la conclusion est simple : inutile de forcer ChatGPT, mieux vaut compléter votre workflow avec le bon outil. En ajoutant un extracteur de texte PDF dédié avec OCR, vous transformez un blocage récurrent en une méthode fiable en deux temps : d’abord extraire le texte du PDF, puis l’analyser. Vous gagnez du temps, et vous pouvez enfin exploiter ChatGPT sur tous vos documents — y compris les PDF scannés, les fichiers image et les mises en page plus complexes.

