
ChatGPT Tidak Bisa Membaca PDF? Ini Penyebabnya + 3 Langkah Perbaikan
Anda punya PDF yang sebenarnya penting banget—bisa berupa paper akademik yang padat, kontrak klien hasil scan, atau satu bab buku pelajaran. Lalu file itu diunggah ke ChatGPT untuk diringkas atau dianalisis, tetapi malah mentok di pesan: “No text could be extracted from this file.” Masalah ini sangat umum dan sering langsung menghambat alur kerja. Kalau Anda sedang menghadapi error ini, Anda tidak sendirian. Penyebabnya juga bukan karena Anda salah pakai—masalah utamanya ada pada keterbatasan dasar ChatGPT dalam membaca jenis PDF tertentu.

Masalah intinya adalah ChatGPT merupakan model bahasa, bukan alat konversi dokumen serbaguna. ChatGPT sangat baik dalam memproses teks digital yang bersih dan rapi. Namun, banyak file PDF—terutama PDF scan atau laporan dengan tata letak rumit—sebenarnya hanyalah gambar berisi teks, bukan teks yang bisa dibaca mesin. ChatGPT tidak memiliki Optical Character Recognition (OCR) bawaan yang dibutuhkan untuk “membaca” dokumen berbasis gambar seperti ini. Ibarat meminta ahli bahasa yang sangat pintar, tetapi tidak bisa melihat, untuk menjelaskan foto halaman buku. Panduan ini akan menjelaskan kenapa error ini muncul dan memberi solusi 3 langkah yang lebih andal agar Anda bisa ekstrak teks dari PDF dengan benar.
Ringkasan Cepat: ChatGPT vs Ekstraktor Teks PDF dengan OCR
Kalau Anda sedang dikejar waktu, ini inti jawabannya. Cara ekstrak teks dari PDF sepenuhnya bergantung pada jenis PDF yang Anda miliki. Apakah itu dokumen teks biasa, atau PDF scan yang sulit dibaca?
Tabel berikut membantu membandingkan antara mengandalkan fitur upload bawaan ChatGPT dan memakai alat yang memang dibuat khusus untuk OCR PDF.
| Fitur / Skenario | ChatGPT (Upload Bawaan) | Ekstraktor OCR Khusus (mis. Lynote) |
|---|---|---|
| PDF Scan / PDF Berbasis Gambar | Gagal (Skor: 1/5) | Sangat baik (Skor: 5/5) |
| Tata Letak Multi-Kolom | Tidak konsisten; teks sering berantakan | Baik; urutan baca tetap terjaga |
| File Dilindungi Kata Sandi | Gagal (Skor: 1/5) | Gagal (memang dibatasi demi keamanan) |
| Kecepatan (untuk PDF bersih) | Cepat untuk file pendek dan sederhana | Cepat; dioptimalkan untuk banyak file sekaligus |
| Paling Cocok Untuk | Menganalisis PDF sederhana yang dibuat langsung dari dokumen digital (mis. ekspor dari Microsoft Word) | Ambil teks dari PDF scan, foto dokumen, atau file dengan layout kompleks |
Skor ini adalah penilaian editorial (1=Buruk, 5=Sangat baik), bukan hasil benchmark terukur.
Kesimpulannya sederhana: jika PDF dibuat langsung dari editor teks seperti Microsoft Word atau Google Docs, ChatGPT mungkin masih bisa membacanya. Tetapi untuk file lain—terutama dokumen yang dipindai, difoto, atau didesain dengan layout berat—Anda memerlukan alat dengan mesin OCR khusus.
4 Penyebab Utama ChatGPT Tidak Bisa Membaca PDF
Mungkin Anda bertanya, “Kalau teksnya terlihat jelas di layar, kenapa ChatGPT tidak bisa membacanya?” Jawabannya ada pada cara file PDF dibuat. PDF tidak selalu berisi teks yang benar-benar bisa diekstrak. Berikut empat penyebab utama di balik error ekstraksi yang sering muncul itu.
1. PDF Berbasis Gambar atau PDF Scan (Penyebab Paling Umum)
Ini adalah alasan kegagalan yang paling sering terjadi. Saat Anda memindai dokumen fisik atau menyimpan file sebagai “image PDF”, yang tersimpan sebenarnya bukan teks, melainkan foto dari halaman tersebut. Bagi komputer, huruf-huruf di file itu tidak berbeda dengan piksel pada gambar pohon.
- Skenarionya: Anda seorang mahasiswa yang ingin menganalisis artikel jurnal 30 halaman hasil scan dari buku perpustakaan. Saat diunggah, ChatGPT hanya melihat kumpulan gambar, bukan isi teksnya.
- Kendala teknisnya: Tanpa Optical Character Recognition (OCR), yaitu proses yang menganalisis gambar lalu mengubah karakter di dalamnya menjadi teks digital, ChatGPT tidak bisa membaca isi dokumen. ChatGPT membutuhkan “lapisan teks” untuk memproses file, sedangkan PDF scan tidak memilikinya.
2. Tata Letak dan Format yang Kompleks
PDF memang unggul untuk mempertahankan tampilan visual—kolom, tabel, header, footer, dan gambar mengambang. Namun, kelebihan ini justru menjadi kendala saat ingin ekstrak teks dari PDF. Parser bawaan ChatGPT cukup dasar; sistem ini lebih cocok untuk alur teks yang lurus dan sederhana.
- Skenarionya: Anda seorang analis bisnis yang sedang membaca laporan riset pasar dengan teks dua kolom, grafik beranotasi, dan tabel data. Saat ChatGPT mencoba membacanya, isi dari beberapa kolom tercampur, sehingga kalimat yang tadinya jelas berubah menjadi kacau.
Pertumbuhan perusahaan pada Q3 didorong oleh strategi pemasaran baru... sangat signifikan, mencapai 5 juta unit... yang berfokus pada media sosial. - Kendala teknisnya: Parser tidak bisa membedakan mana jeda antar-kolom dan mana akhir paragraf. Sistem membaca teks berdasarkan posisi di halaman, bukan berdasarkan alur logisnya, sehingga hasil ekstraksinya sering berantakan.
3. File Dilindungi Kata Sandi atau Terenkripsi
Yang ini lebih mudah dipahami. Jika sebuah PDF memerlukan kata sandi untuk dibuka atau memiliki pembatasan penyalinan teks, ChatGPT akan mengikuti pengaturan keamanan tersebut. ChatGPT tidak akan—dan memang tidak bisa—melewatinya.
- Skenarionya: Rekan kerja mengirim laporan keuangan sensitif yang dilindungi kata sandi untuk dianalisis. Anda tidak bisa langsung mengunggahnya lalu berharap ChatGPT dapat membukanya sendiri.
- Kendala teknisnya: Isi file terenkripsi. Sebelum dibuka dengan kata sandi yang benar, datanya tidak bisa dibaca oleh aplikasi apa pun, termasuk model AI.
4. File Rusak atau Encoding Tidak Standar
Memang lebih jarang, tetapi tetap mungkin terjadi. File PDF bisa saja rusak atau memakai encoding teks yang tidak dikenali parser ChatGPT. Hal ini dapat terjadi karena unduhan yang gagal, proses konversi file yang bermasalah, atau dokumen lama dengan format tidak umum. Lapisan teksnya mungkin secara teknis ada, tetapi tersusun kacau sehingga tidak bisa diakses dengan benar.
Intinya: Alasan utama alat khusus lebih unggul daripada ChatGPT untuk ekstrak teks dari PDF adalah karena alat tersebut memiliki mesin Optical Character Recognition (OCR) bawaan, yang memang dirancang untuk mengubah gambar berisi teks menjadi karakter yang bisa dibaca mesin dan dipahami AI.
Solusinya: Cara Ekstrak Teks dari PDF Apa Pun dengan Andal dalam 3 Langkah
Saat ChatGPT gagal membaca PDF, jangan buang waktu mencoba prompt yang berbeda-beda atau upload ulang file yang sama. Solusi paling cepat adalah memproses PDF lebih dulu dengan alat yang memang dibuat untuk tugas ini. Menggunakan alat transkripsi dan ekstraksi data berbasis AI dengan mesin OCR yang kuat adalah cara paling andal untuk ekstrak teks dari PDF scan atau PDF yang rumit.
Berikut caranya dalam waktu kurang dari satu menit dengan alat seperti Transkripsi AI Lynote, yang gratis untuk penggunaan dasar dan tidak perlu akun untuk mulai.
Langkah 1. Upload file PDF yang bermasalah
Pertama, buka ekstraktor teks PDF dari Lynote. Alih-alih upload file ke ChatGPT, langsung drag and drop PDF yang bermasalah ke area upload Lynote. Anda juga bisa klik untuk menelusuri komputer lalu memilih file. Cara ini sangat cocok untuk catatan kuliah hasil scan, laporan dengan layout kompleks, atau dokumen berbasis gambar yang biasanya langsung ditolak ChatGPT.

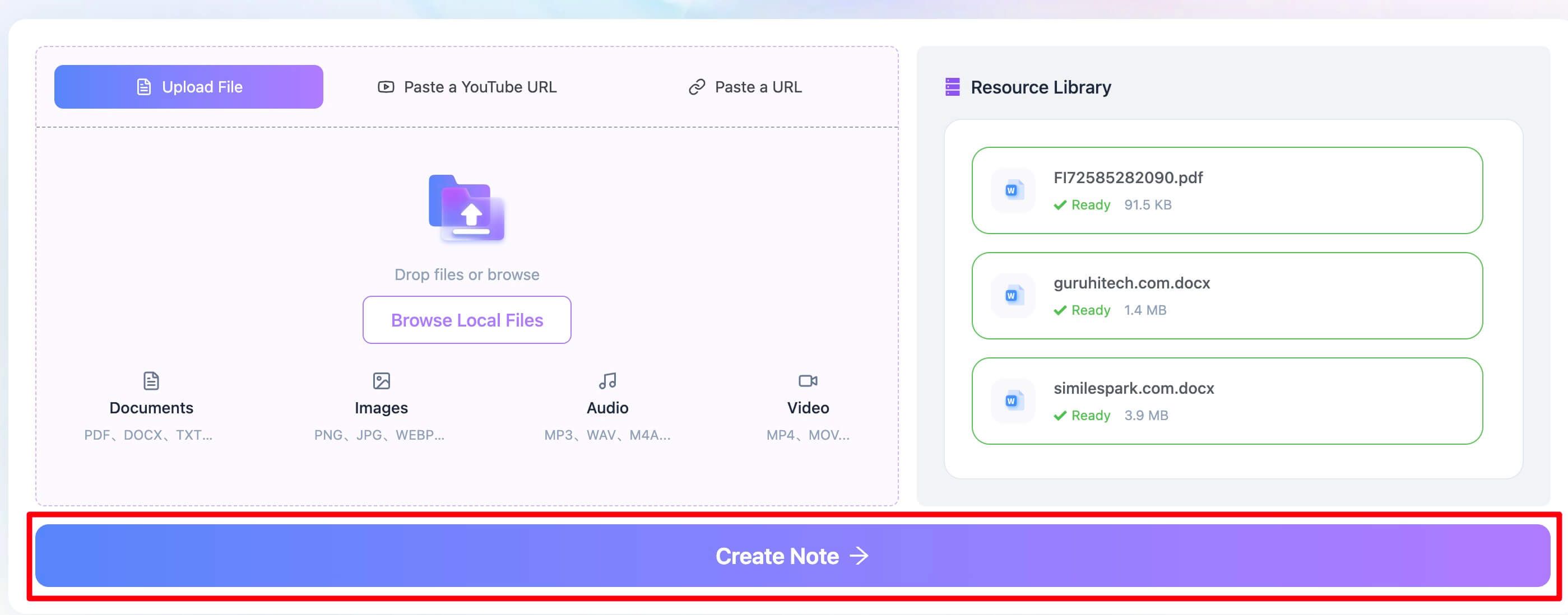
Langkah 2. Ekstrak teks dari PDF
Setelah file terupload, cukup klik tombol "Create Note". Ini adalah langkah paling penting. Sistem Lynote akan langsung memproses dokumen Anda dengan mesin OCR yang andal. Sistem ini tidak hanya mencari lapisan teks yang sudah ada, tetapi juga menganalisis halaman sebagai gambar, mengenali karakter, lalu menyusun ulang teksnya secara digital. Dukungan lebih dari 130 bahasa juga membuatnya efektif untuk dokumen internasional.
Langkah 3. Tinjau dan salin teks PDF
Dalam hitungan detik, teks hasil ekstraksi yang rapi akan muncul di editor online. Sekarang Anda sudah punya sumber teks yang bisa dibaca ChatGPT dengan mudah. Anda bisa mengecek cepat jika ada kesalahan OCR yang terlihat, melakukan edit kecil, lalu menyalin seluruh teksnya. Setelah itu, tempel langsung ke prompt ChatGPT untuk analisis, ringkasan, atau pertanyaan Anda. Anda juga bisa mengunduh teks sebagai file .txt untuk dipakai nanti.

Proses tiga langkah ini efektif menjembatani PDF berbasis gambar Anda agar bisa dibaca di lingkungan berbasis teks milik ChatGPT.

Setelah masalah teratasi: fitur penting dalam alat ekstrak teks PDF
Begitu Anda sadar bahwa dibutuhkan alat khusus, Anda akan menemukan banyak pilihan. Jadi, apa yang membedakan alat yang benar-benar bagus dari yang biasa saja? Berikut fitur utama yang perlu diperhatikan, terutama jika Anda sering menangani dokumen.
- OCR dengan akurasi tinggi: Ini wajib. Tugas utama alat ini adalah mengubah gambar menjadi teks dengan akurat. Mesin OCR yang bagus akan meminimalkan kesalahan (misalnya
lterbaca sebagai1ataurnterbaca sebagaim) dan mampu menangani berbagai font serta resolusi. - Dukungan banyak bahasa: Jika Anda bekerja dengan dokumen internasional, paper riset, atau teks historis, pastikan alat tersebut bisa mengenali karakter dan tanda diakritik dari bahasa yang Anda butuhkan. Alat seperti Lynote, yang mendukung 130+ bahasa, memberi fleksibilitas yang sangat penting.
- Pemrosesan batch: Sedang mencoba ambil teks dari PDF scan dalam satu folder invoice atau belasan paper riset? Alat yang memungkinkan upload banyak file sekaligus dan memprosesnya dalam antrean akan sangat menghemat waktu dibanding mengerjakannya satu per satu.
- Opsi ekspor yang fleksibel: Berhasil mengekstrak teks baru setengah pekerjaan. Anda juga harus bisa langsung memakainya. Cari opsi praktis sekali klik untuk salin ke clipboard, unduh sebagai file .txt atau .docx, atau lanjut integrasi ke alur kerja lain. Alat modern bahkan bisa memungkinkan Anda chat dengan dokumen atau menerjemahkan teks hasil ekstraksi di antarmuka yang sama.
Memilih alat dengan fitur-fitur ini bisa mengubah hambatan yang menjengkelkan menjadi bagian yang mulus dari alur kerja riset dan analisis Anda.
Tips praktis: mengatasi teks hasil ekstraksi yang berantakan atau kurang akurat
Bahkan teknologi OCR terbaik pun tidak selalu sempurna 100%, terutama untuk scan berkualitas rendah, catatan tulisan tangan, atau layout yang sangat kompleks. Jika hasil ekstrak teks dari PDF terlihat agak berantakan, jangan panik. Berikut beberapa trik praktis untuk merapikannya dengan cepat.
- Perbaiki paragraf yang terputus atau menyatu: Jika teks dari beberapa kolom tergabung, Anda akan melihat baris panjang yang sulit dibaca. Cara tercepat adalah menempelkan teks ke editor sederhana (seperti Notepad atau TextEdit) lalu tekan "Enter" secara manual untuk mengembalikan jeda paragraf. Hanya butuh sebentar, tetapi hasilnya jauh lebih mudah dibaca, baik oleh Anda maupun oleh ChatGPT.
- Gunakan Find and Replace untuk kesalahan umum: OCR punya kesalahan klasik. Jika Anda melihat banyak angka
1yang seharusnya hurufl, atau tanda!yang seharusnyai, gunakan fitur "Find and Replace" di editor teks Anda (Ctrl+H atau Cmd+Shift+H). Beberapa penggantian yang tepat bisa membersihkan 90% kesalahan hanya dalam hitungan detik. - Sederhanakan sebelum minta ringkasan: Sebelum menempelkan teks yang sudah dibersihkan ke ChatGPT untuk diringkas, pertimbangkan menghapus bagian yang tidak relevan seperti header, footer, nomor halaman, dan caption gambar. Ini membantu AI fokus pada isi utama dan sering menghasilkan output yang lebih akurat serta ringkas.
Sedikit perapian di awal bisa mengurangi banyak kebingungan dan memberi hasil analisis AI yang jauh lebih baik.
Pertanyaan yang sering diajukan
Apakah ChatGPT-4o bisa membaca teks dari PDF scan?
Tidak, tidak secara langsung. Bahkan model yang lebih canggih seperti GPT-4o masih belum memiliki mesin OCR bawaan yang bisa dipakai pengguna pada fitur upload file standar. Jika Anda upload PDF scan atau PDF yang hanya berisi gambar, Anda akan tetap mendapatkan error "no text could be extracted". Solusinya, gunakan OCR PDF online atau alat OCR lain terlebih dahulu untuk konversi PDF ke teks, lalu tempelkan teks tersebut ke prompt Anda.
Kenapa copy-paste dari PDF saya bisa, tapi ChatGPT tetap gagal?
Ini pertanyaan bagus karena menunjukkan bahwa PDF punya lapisan yang tidak selalu terlihat. Banyak file PDF memiliki lapisan gambar (yang Anda lihat) sekaligus lapisan teks tersembunyi (yang dibuat saat file dibuat). Saat Anda menyorot lalu menyalin teks, pembaca PDF seperti Adobe Acrobat atau Preview mengambilnya dari lapisan teks tersembunyi itu. Namun, jika lapisan teks tersebut rusak, hilang, atau encoding-nya buruk, parser sederhana di sisi server milik ChatGPT tidak bisa membacanya, meskipun software di komputer Anda masih bisa.
Apakah ada cara gratis agar PDF saya bisa dibaca ChatGPT?
Ya. Metode yang dijelaskan di artikel ini dengan versi gratis alat seperti Lynote adalah salah satu opsi gratis paling efektif. Alat ini memakai mesin OCR berkualitas tinggi tanpa mewajibkan pembayaran atau akun untuk ekstraksi dasar. Memang ada alat OCR gratis lain di internet, tetapi sering dipenuhi iklan, akurasinya rendah, atau membatasi ukuran file dengan sangat ketat.
Kenapa formatnya (tebal, miring) hilang setelah teks diekstrak?
Alat ekstrak teks, terutama yang berbasis OCR, fokus utamanya adalah menangkap karakter teks, bukan mempertahankan format rich text. Karena itu, hasilnya hampir selalu berupa teks polos. Untuk AI, ini justru biasanya lebih ideal karena model lebih mengutamakan isi dan makna teks, bukan tampilan visualnya.
Kesimpulan: Pakai alat yang memang sesuai kebutuhannya
ChatGPT adalah alat yang sangat kuat untuk bekerja dengan bahasa, tetapi bukan solusi serbaguna untuk semua format file. Error "no text could be extracted from this file" bukan bug, melainkan batas kemampuan sistem. Model ini dirancang untuk memproses teks yang bersih dan digital, bukan membaca gambar berisi teks yang terkunci di dalam PDF scan atau tata letak PDF yang rumit.
Bagi pelajar, peneliti, dan profesional yang rutin menangani berbagai jenis dokumen, pesannya jelas: jangan memaksa satu alat untuk semua pekerjaan—lengkapi alur kerja Anda dengan alat yang tepat. Dengan menambahkan ekstraktor teks PDF berbasis OCR ke workflow Anda, masalah yang tadinya terus berulang bisa berubah menjadi proses dua langkah yang jauh lebih andal: ekstrak dulu, lalu analisis. Cara ini bukan hanya menghemat waktu, tetapi juga membantu Anda memaksimalkan AI untuk semua dokumen, termasuk PDF scan dan file kompleks yang sering tidak bisa dibaca ChatGPT.

