
ChatGPT не может прочитать PDF? Причина и решение за 3 шага
У вас на руках вроде бы идеальный PDF: плотная научная статья, отсканированный договор с клиентом или глава из учебника. Вы загружаете файл в ChatGPT, рассчитывая быстро получить краткое содержание или разбор, и тут упираетесь в ошибку: «Не удалось извлечь текст из этого файла». Это очень частая и раздражающая проблема, которая полностью ломает рабочий процесс. Если вы уже видели это сообщение, вы не одиноки — и дело не в вас. Просто многие неправильно понимают, для чего именно создан ChatGPT.

Главная причина в том, что ChatGPT — это языковая модель, а не универсальный конвертер документов. Он отлично работает с чистым цифровым текстом. Но многие PDF, особенно сканы и сложные отчёты, по сути представляют собой изображения текста, а не сам текст. У ChatGPT нет встроенного OCR, чтобы «прочитать» такие PDF на основе изображений. Это как просить блестящего лингвиста, который не видит, описать фотографию книжной страницы. В этом руководстве мы разберём, почему возникает эта ошибка, и покажем надёжное решение из трёх шагов, чтобы извлечь текст из PDF и продолжить работу.
Быстрый вывод: ChatGPT или специальный инструмент для извлечения текста из PDF
Если времени мало, вот главное. Способ, которым вы сможете распознать текст из PDF, полностью зависит от типа файла. Это обычный PDF с текстовым слоем или проблемный скан в виде изображения?
Эта таблица поможет понять, что выбрать: пытаться обойтись встроенной загрузкой в ChatGPT или сразу использовать OCR для PDF онлайн в специализированном инструменте.
| Функция / сценарий | ChatGPT (встроенная загрузка) | Специальный OCR-экстрактор (например, Lynote) |
|---|---|---|
| Сканированный PDF / PDF только с изображениями | Не справляется (оценка: 1/5) | Отлично (оценка: 5/5) |
| Многоколоночная вёрстка | Нестабильно; часто путает текст | Хорошо; сохраняет порядок чтения |
| Файлы, защищённые паролем | Не справляется (оценка: 1/5) | Не справляется (это ограничение безопасности) |
| Скорость (для простых PDF) | Быстро для коротких и простых файлов | Быстро; оптимизировано для больших объёмов |
| Лучший сценарий использования | Анализ простых PDF, изначально созданных в цифровом виде (например, экспорт из Word) | Распознавание сканированного PDF, фото документов и файлов со сложной вёрсткой |
Оценки в таблице — редакционная шкала для удобства (1 = плохо, 5 = отлично), а не результаты лабораторных тестов.
Вывод простой: если PDF был создан напрямую в текстовом редакторе, например в Microsoft Word или Google Docs, ChatGPT может с ним справиться. Но во всех остальных случаях — особенно если документ сканировали, фотографировали или делали со сложным дизайном — нужен инструмент с отдельным OCR-движком.
4 главные причины, почему ChatGPT не читает PDF
Вы можете подумать: «Если я вижу текст на экране, почему ChatGPT его не видит?» Ответ кроется в том, как устроены PDF-файлы. PDF не всегда так прост, как кажется. Ниже — четыре основные причины, почему появляется эта ошибка извлечения.
1. PDF в виде изображения или скана — самая частая причина
Это, безусловно, самый распространённый источник проблемы. Когда вы сканируете бумажный документ или сохраняете файл как PDF-изображение, вы сохраняете не текст, а снимок страницы. Для компьютера буквы в таком файле ничем не отличаются от пикселей на фотографии дерева.
- Сценарий: Вы студент и пытаетесь проанализировать 30-страничную журнальную статью, которую преподаватель отсканировал из библиотечной книги. Вы загружаете файл, а ChatGPT видит только набор изображений.
- Техническая причина: Без Optical Character Recognition (OCR) — технологии, которая анализирует изображения, распознаёт символы и превращает их в цифровой текст, — ChatGPT просто не видит содержимое. Ему нужен текстовый слой, а в сканированных PDF его нет.
2. Сложная вёрстка и форматирование
PDF отлично сохраняет визуальную структуру: колонки, таблицы, заголовки, колонтитулы и плавающие изображения. Но именно это часто мешает извлечению текста. Встроенный парсер ChatGPT довольно базовый и лучше всего работает с простым линейным потоком текста.
- Сценарий: Вы бизнес-аналитик и работаете с отчётом по исследованию рынка, где есть двухколоночный текст, графики с выносками и таблицы с данными. Когда ChatGPT пытается его прочитать, текст из разных колонок перемешивается, и связные предложения превращаются в бессмыслицу.
Рост компании в 3 квартале был связан с новой маркетинговой... впечатляющий результат, достигнув 5 миллионов единиц... стратегией с упором на социальные сети. - Техническая причина: Парсер не всегда понимает, где заканчивается колонка и начинается новый абзац. Он читает текст по расположению на странице, а не по логике документа, поэтому на выходе получается путаница.
3. Файлы, защищённые паролем или шифрованием
Здесь всё проще. Если PDF требует пароль для открытия или запрещает копирование текста, ChatGPT соблюдает эти ограничения безопасности. Он не будет и не может их обходить.
- Сценарий: Коллега отправляет вам конфиденциальный финансовый отчёт, защищённый паролем, и просит помочь с анализом. Просто загрузить его в ChatGPT и ждать результата не получится.
- Техническая причина: Содержимое файла зашифровано. Пока документ не разблокирован правильным паролем, данные остаются нечитаемыми для любого приложения, включая AI-модели.
4. Повреждённый файл или нестандартная кодировка
Такое встречается реже, но тоже возможно: сам PDF может быть повреждён или использовать необычную кодировку текста, которую парсер ChatGPT не распознаёт. Это бывает из-за неудачной загрузки, ошибки при конвертации файла или при работе со старыми документами. Текстовый слой может формально существовать, но быть повреждённым настолько, что извлечь его не удаётся.
Главное: специализированный инструмент лучше справляется с извлечением текста из PDF, чем ChatGPT, потому что в нём есть встроенный OCR-движок, специально созданный для того, чтобы преобразовывать изображения текста в машиночитаемые символы, понятные AI.
Решение: как извлечь текст из любого PDF за 3 шага
Если ChatGPT не может прочитать PDF, не тратьте время на новые промпты и повторную загрузку одного и того же файла. Гораздо быстрее сначала обработать документ в инструменте, который специально умеет извлекать текст из PDF. Надёжнее всего работает сервис с OCR для PDF онлайн: он распознаёт текст даже в сканах и сложных файлах.
Вот как сделать это меньше чем за минуту с помощью сервиса вроде транскрибации с AI от Lynote: базовые функции доступны бесплатно, и для старта не нужен аккаунт.
Шаг 1. Загрузите проблемный PDF-файл
Сначала откройте инструмент Lynote для извлечения текста из PDF. Вместо того чтобы загружать файл в ChatGPT, просто перетащите проблемный PDF в область загрузки Lynote. Можно и просто выбрать файл с компьютера вручную. Это особенно удобно, если ChatGPT не видит текст в PDF со сканами лекций, сложными отчётами или документами, где страницы сохранены как изображения.

Шаг 2. Извлеките текст из PDF
После загрузки файла просто нажмите кнопку "Create Note". Это ключевой шаг. Дальше Lynote сразу начинает распознавать текст из PDF с помощью мощного OCR-движка. Сервис не просто ищет готовый текстовый слой: он анализирует страницу как изображение, распознаёт символы и заново собирает текст в цифровом виде. Поддерживается более 130 языков, поэтому инструмент подходит и для международных документов.
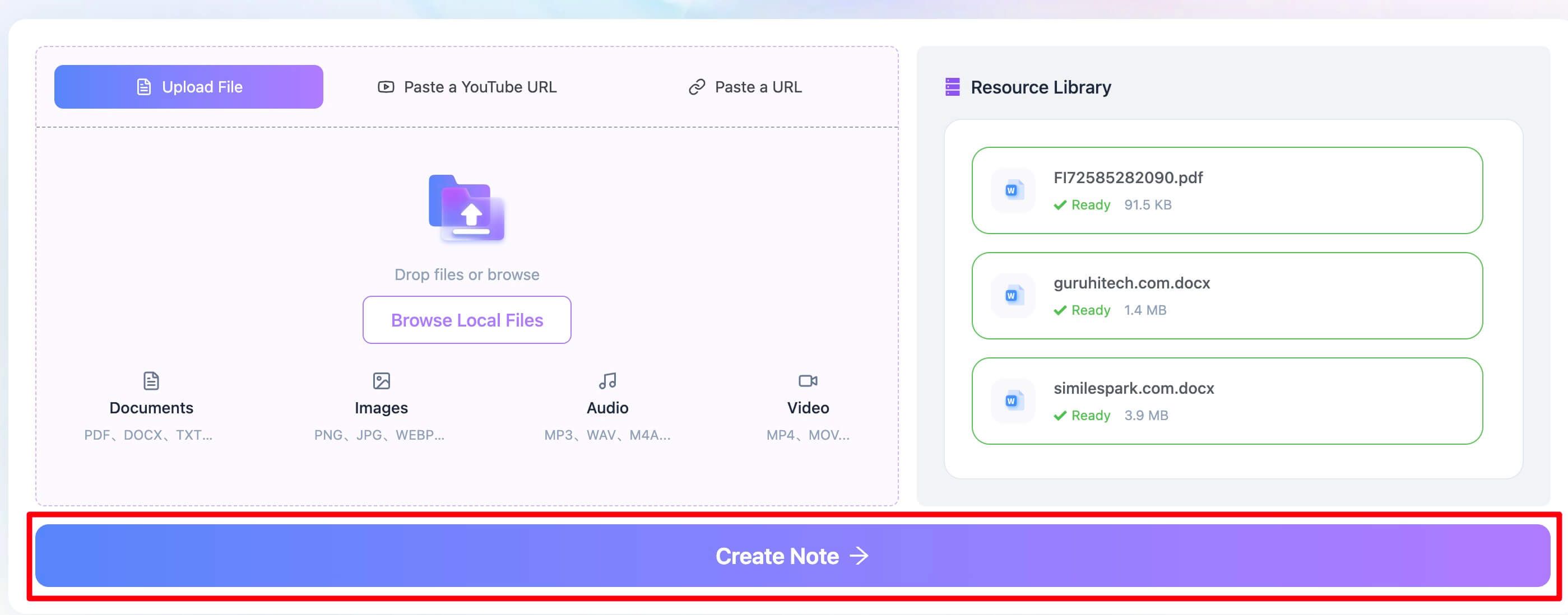
Шаг 3. Проверьте и скопируйте текст из PDF
Уже через несколько секунд в онлайн-редакторе появится чистый извлечённый текст. Теперь у вас есть текстовая версия документа, которую ChatGPT сможет нормально обработать. Быстро просмотрите результат, исправьте явные OCR-ошибки при необходимости и скопируйте весь текст. После этого просто вставьте его в prompt ChatGPT и переходите к анализу, краткому пересказу или своему запросу. При желании текст можно скачать и как файл .txt для дальнейшей работы.

Этот простой сценарий из трёх шагов закрывает разрыв между PDF на основе изображений и текстовым форматом, который понимает ChatGPT.

Что важно в инструменте для извлечения текста из PDF
Когда становится понятно, что нужен отдельный инструмент, вариантов оказывается много. Но чем действительно хороший сервис отличается от посредственного? Вот на какие функции стоит смотреть в первую очередь, особенно если вы регулярно работаете с документами.
- Высокая точность OCR: Это обязательное условие. Главная задача сервиса — точно конвертировать PDF в текст онлайн. Хороший движок сводит к минимуму ошибки вроде путаницы между
lи1илиrnиm, а также нормально работает с разными шрифтами и качеством сканов. - Поддержка разных языков: Если вы работаете с международными документами, научными статьями или архивными материалами, убедитесь, что сервис корректно распознаёт нужные языки, символы и диакритику. Инструменты вроде Lynote с поддержкой 130+ языков дают здесь заметно больше гибкости.
- Пакетная обработка: Нужно распознать текст из PDF сразу для папки со сканами счетов или для десятка научных статей? Возможность загрузить несколько файлов сразу и обработать их по очереди экономит массу времени по сравнению с ручной работой по одному документу.
- Гибкие варианты экспорта: Извлечь текст — это только половина задачи. Важно ещё удобно его использовать. Ищите сервис с простыми опциями: скопировать в буфер обмена, скачать как файл .txt или .docx или продолжить работу дальше. Современные инструменты также могут позволять сразу общаться с документом или переводить извлечённый текст в том же интерфейсе.
Если выбрать сервис с такими возможностями, проблема перестаёт быть раздражающим препятствием и становится обычной частью рабочего процесса для исследования и анализа.
Полезный совет: что делать, если текст после распознавания получился грязным
Даже лучший OCR не даёт идеальный результат в 100% случаев — особенно если у вас некачественный скан, рукописные заметки или очень сложная вёрстка. Если после распознавания сканированного PDF текст получился немного «ломаным», это не критично. Вот несколько практичных приёмов, которые помогут быстро привести его в порядок.
- Исправьте сломанные абзацы: Если текст из колонок склеился, вы увидите длинные строки без нормальных переносов. Самый быстрый способ — вставить текст в простой редактор вроде Notepad или TextEdit и вручную нажать "Enter" там, где нужно восстановить абзацы. Это займёт минуту, но текст станет намного удобнее читать и вам, и ChatGPT.
- Используйте поиск и замену для типичных ошибок: У OCR есть классические промахи. Если в тексте слишком много
1вместоlили!вместоi, откройте функцию "Найти и заменить" в редакторе (Ctrl+H или Cmd+Shift+H). Пара точечных замен может убрать до 90% ошибок за считанные секунды. - Упростите текст перед тем, как отправлять его на сводку: Прежде чем вставлять очищенный текст в ChatGPT для краткого пересказа, удалите лишнее — колонтитулы, номера страниц, подписи к рисункам и другие второстепенные элементы. Так AI сосредоточится на основном содержании и чаще выдаст более точный и лаконичный результат.
Небольшая предварительная очистка текста помогает избежать путаницы и заметно улучшает результат AI-анализа.
Часто задаваемые вопросы
Может ли ChatGPT-4o прочитать текст из сканированного PDF?
Нет, не напрямую. Даже более продвинутые модели вроде GPT-4o по-прежнему не имеют встроенного пользовательского OCR в стандартной загрузке файлов. Если загрузить сканированный PDF, где страницы представлены только как изображения, вы получите ту же ошибку в духе «не удалось извлечь текст из PDF». Сначала нужно распознать текст из PDF через внешний OCR-инструмент, а затем вставить этот текст в свой prompt.
Почему я могу копировать текст из PDF вручную, а ChatGPT не справляется?
Это хороший вопрос, потому что он показывает, как устроен PDF внутри. Во многих PDF есть сразу два слоя: слой изображения, который вы видите, и скрытый текстовый слой, созданный при формировании файла. Когда вы выделяете и копируете текст, PDF-просмотрщик вроде Adobe Acrobat или Preview берёт данные именно из этого скрытого слоя. Но если этот слой повреждён, отсутствует или закодирован нестандартно, более простой серверный парсер ChatGPT не сможет его прочитать — даже если локальная программа на вашем компьютере справляется без проблем.
Есть ли бесплатный способ сделать текст в PDF читаемым для ChatGPT?
Да. Способ из этой статьи с использованием бесплатного тарифа сервиса вроде Lynote — один из самых эффективных бесплатных вариантов. Он позволяет извлечь текст из PDF с помощью качественного OCR без оплаты и без регистрации для базовых задач. Другие бесплатные OCR-сервисы тоже существуют, но у них часто много рекламы, ниже точность или слишком жёсткие ограничения по размеру файла.
Почему после извлечения пропало форматирование (жирный, курсив)?
Инструменты для извлечения текста, особенно решения на базе OCR, в первую очередь распознают сами символы, а не сохраняют форматирование вроде жирного шрифта, курсива и других элементов rich text. Поэтому на выходе почти всегда получается обычный текст без оформления. Для AI-моделей это обычно даже удобнее: им важнее смысл и содержание, а не визуальное оформление.
Вывод: используйте подходящий инструмент
ChatGPT — революционный инструмент для работы с текстом, но это не универсальное решение для любых форматов файлов. Ошибка "не удалось извлечь текст из PDF" — не баг, а ограничение самого инструмента. Модель умеет хорошо обрабатывать чистый цифровой текст, но не предназначена для того, чтобы надёжно распознавать текст на изображениях внутри сканов или разбирать сложную вёрстку PDF.
Для студентов, исследователей и специалистов, которые регулярно работают с разными документами, вывод простой: не пытайтесь заставить один инструмент делать всё — лучше дополните его подходящим решением. Если добавить в свой процесс отдельный инструмент, который помогает извлечь текст из PDF с помощью OCR, постоянная проблема превращается в понятный сценарий из двух шагов: сначала распознать текст из PDF, потом вставить его в ChatGPT для анализа или краткого вывода. Такой подход не только экономит время, но и позволяет полноценно работать с любыми документами — не только с простыми файлами, но и там, где нужно распознавание сканированного PDF, OCR для PDF онлайн или конвертировать PDF в текст без лишних ошибок.

