
ChatGPTでPDFを読めない理由と3ステップ解決法
完璧なPDFを用意したのに、うまくいかない。内容の濃い学術論文、スキャンした取引先との契約書、教科書の1章――そんなPDFをChatGPTにアップロードして、要約や分析を頼もうとした瞬間、**「このファイルからテキストを抽出できませんでした」**と表示される。これはかなりよくあるつまずきで、作業がそこで止まってしまいます。このエラーメッセージに悩まされているのは、あなただけではありません。原因は操作ミスではなく、ChatGPTがそもそも何を得意とするツールなのか、という点にあります。

根本的な問題は、ChatGPTが言語モデルであって、あらゆる文書を変換できる万能ツールではないことです。きれいなデジタルテキストの処理は得意ですが、多くのPDF、特にスキャンPDFや複雑なレポートは、実際には「文字データ」ではなく「文字が写った画像」です。こうした画像PDFを“読む”には、内蔵のOCR(光学文字認識)が必要ですが、ChatGPTはそこを前提にした専用ツールではありません。たとえるなら、本のページの写真を見せて説明してほしいのに、写真そのものは見えない優秀な言語学者に頼んでいるようなものです。このガイドでは、なぜこのエラーが起きるのかをわかりやすく整理し、PDF テキスト抽出を安定して行うための3ステップ解決法を紹介します。
すぐ結論:ChatGPTとPDFテキスト抽出ツールの違い
急いでいる方向けに、先に結論をお伝えします。PDFから文字を抽出できるかどうかは、手元のPDFの種類でほぼ決まります。普通のテキストPDFなのか、それともスキャンPDFや画像ベースのPDFなのか――ここが分かれ目です。
以下の表では、ChatGPTの標準アップロードで対応する場合と、専用のPDF OCRツールを使う場合の違いを整理しています。
| 機能 / ケース | ChatGPT(標準アップロード) | OCR対応の専用抽出ツール(例:Lynote) |
|---|---|---|
| スキャンPDF / 画像PDF | ほぼ不可(評価: 1/5) | 非常に優秀(評価: 5/5) |
| 複数カラムのレイアウト | 精度が不安定で、文字順が崩れやすい | 良好。読み順を保ちやすい |
| パスワード付きPDF | 不可(評価: 1/5) | 不可(セキュリティ仕様による) |
| 処理速度(きれいなPDF) | 短く単純なPDFなら速い | 速い。大量処理にも向く |
| 向いている用途 | シンプルなテキストPDFの分析(例:Microsoft Wordから書き出した文書) | スキャン文書、書類写真、複雑なレイアウトのPDFから文字を抽出する用途 |
評価は編集部による目安です(1=低い、5=高い)。実測ベンチマークではありません。
要点はシンプルです。Microsoft WordやGoogle Docsのようなテキストエディタから直接作成したPDFなら、ChatGPTでも読めることがあります。ですが、スキャンした文書、写真をPDF化したもの、デザイン要素の多い資料などでは、専用OCRエンジンを備えたツールが必要です。
ChatGPTがPDFを読めない主な4つの原因
「画面では文字が見えているのに、なぜChatGPTでは読めないの?」と思うかもしれません。答えは、PDFの作られ方にあります。PDFは見た目どおりとは限りません。ここでは、あの厄介な抽出エラーを引き起こす代表的な4つの原因を見ていきます。
1. 画像だけのPDF・スキャンPDF(最も多い原因)
これは圧倒的によくある原因です。紙の書類をスキャンしたり、ファイルを「画像PDF」として保存した場合、保存されているのは文字そのものではありません。ページ全体の写真です。コンピュータから見ると、その中の文字は木の写真のピクセルと同じで、ただの画像情報にすぎません。
- よくある場面: 学生が、先生から配られた図書館の本をスキャンした30ページの論文を分析しようとしているケース。アップロードしても、ChatGPTには画像の集まりとしてしか認識されません。
- 技術的な理由: 画像を解析して文字を認識し、デジタルテキストに変換するOCR(光学文字認識)がなければ、ChatGPTは内容を読めません。ChatGPTが読むには文字レイヤーが必要ですが、スキャンPDFにはそれがないのです。
2. 複雑なレイアウトや書式
PDFは、段組み、表、ヘッダー、フッター、回り込み画像など、見た目を保ったまま共有できるのが強みです。ただし、その強みがPDF 文字抽出では弱点になることがあります。ChatGPTの内蔵パーサーは基本的な構造を前提としており、素直に上から下へ流れるテキストには向いていても、複雑な誌面構成には強くありません。
- よくある場面: 2段組みの本文、注釈付きグラフ、データ表が並ぶ市場調査レポートを、ビジネスアナリストが読み込ませたいケース。ChatGPTで処理すると左右のカラムが混ざり、文章の順番が崩れて意味不明になってしまいます。
第3四半期の成長は新しいマーケティング施策の結果で… 顕著で、500万台に到達し… SNS重視の戦略によって… - 技術的な理由: パーサーは、段組みの切れ目と段落の終わりを正確に見分けられないことがあります。論理的な文章の流れではなく、ページ上の位置をもとに読もうとするため、テキストの順序が崩れやすいのです。
3. パスワード付きPDF・暗号化されたファイル
これは比較的わかりやすい原因です。PDFを開くのにパスワードが必要だったり、PDFから文字をコピーできないよう制限がかかっていたりする場合、ChatGPTはそのセキュリティ設定に従います。回避しようとはしませんし、実際に回避もできません。
- よくある場面: 同僚から、分析用に機密性の高い財務レポートがパスワード付きPDFで送られてくるケース。そのままアップロードしても、ChatGPTが中身を開いてくれるわけではありません。
- 技術的な理由: ファイル内容が暗号化されているためです。正しいパスワードで解除されるまでは、AIモデルを含むどのアプリケーションからも内容を読み取れません。
4. ファイル破損や特殊な文字エンコーディング
頻度は高くありませんが、PDFファイル自体が壊れていたり、ChatGPTのパーサーが認識しにくい特殊な文字エンコーディングを使っていたりすることもあります。ダウンロード失敗、不完全な変換、古い文書の扱いなどで起こりがちです。文字レイヤー自体は存在していても、内部的に崩れていてアクセスできない状態になっている場合があります。
結論: PDF テキスト抽出で専用ツールがChatGPTより強い最大の理由は、OCR(光学文字認識)エンジンを内蔵していることです。 OCRは、文字が写った画像をAIが扱える機械可読な文字データへ変換するために設計されています。
解決策:あらゆるPDFから文字を抽出する3ステップ
ChatGPTで読めないPDFに何度もプロンプトを変えたり、同じファイルを再アップロードしたりしても時間の無駄です。解決策は、PDF 文字抽出専用のツールで先にテキスト化しておくこと。OCR性能の高いAI文字起こし・データ抽出ツールを使うのが、いちばん確実です。
やり方は1分もかかりません。たとえば、基本機能を無料で使えて、アカウント登録なしですぐ始められるLynote AI文字起こしを使えば簡単です。
Step 1. 読めないPDFをアップロード
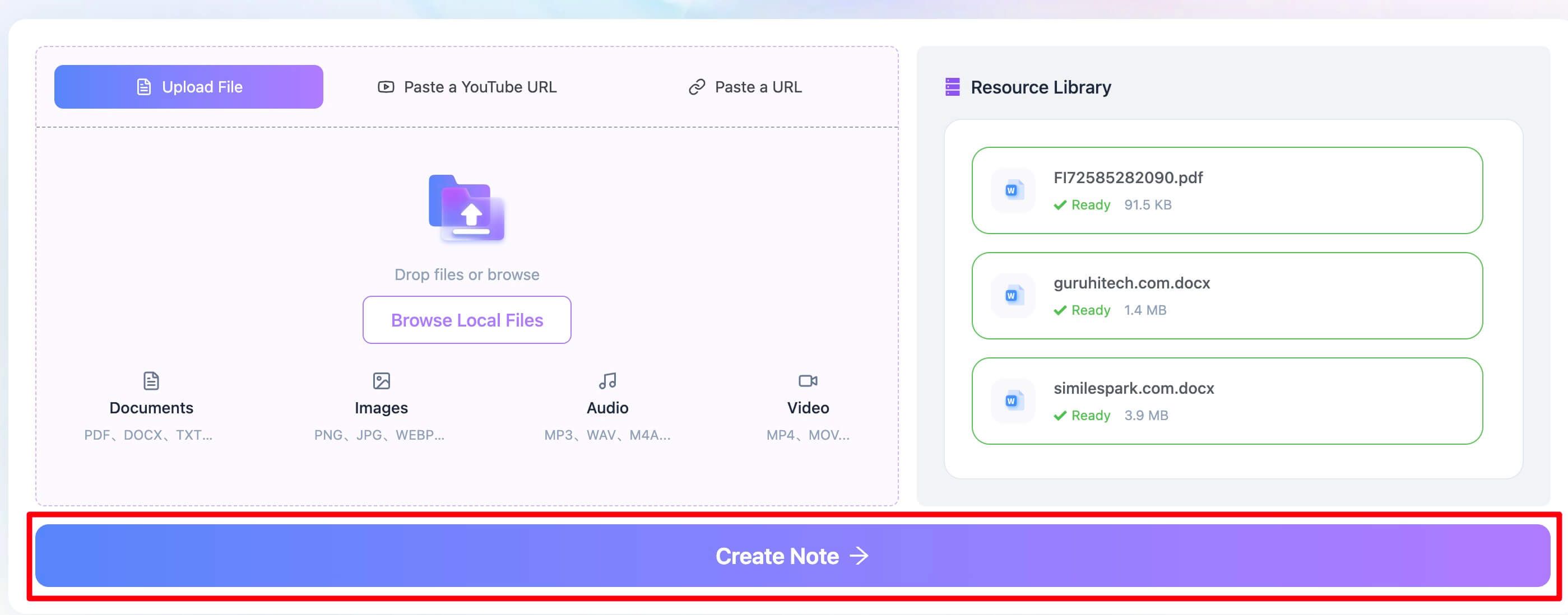
まずは、LynoteのPDFテキスト抽出ツールを開きます。ChatGPTに直接アップロードする代わりに、問題のあるPDFをLynoteのアップロード欄へドラッグ&ドロップしてください。クリックしてPC内のファイルを選ぶこともできます。ChatGPTではじかれやすい、スキャンした講義ノート、複雑なレポート、画像PDFのテキスト抽出にも向いています。

Step 2. PDFから文字を抽出
ファイルをアップロードしたら、**「Create Note」**ボタンをクリックするだけです。ここが重要なポイントです。Lynoteのバックエンドがすぐに処理を開始し、高性能なOCRエンジンで文書を解析します。既存のテキストレイヤーを探すだけではなく、ページ全体を画像として認識し、文字を特定してデジタルテキストとして再構成します。130以上の言語に対応しているため、多言語の文書でも使いやすいです。
Step 3. 抽出したPDFテキストを確認してコピー
数秒後、抽出されたテキストがオンラインエディタにきれいに表示されます。これで、ChatGPTが読み取りやすいテキストベースの元データが用意できます。OCRの誤認識がないかをざっと確認し、必要なら軽く修正してから、全文をコピーしてください。あとはそのままChatGPTのプロンプトに貼り付ければ、要約・分析・質問に進めます。将来使うために、テキストを.txtファイルとしてダウンロードすることも可能です。

この3ステップで、画像PDFとChatGPTのあいだにある“読めない壁”をスムーズに埋められます。

PDFテキスト抽出ツールの選び方
専用ツールが必要だと分かると、候補はたくさん見つかります。では、使えるツールと微妙なツールの違いは何でしょうか。とくに日常的に文書を扱うなら、次のポイントをチェックしてください。
- OCR精度が高いこと: ここは妥協できません。PDF OCRツールの役割は、画像を正確に文字へ変換することです。優れたエンジンなら、
lと1、rnとmの取り違えのようなミスを減らし、さまざまなフォントや解像度にも対応できます。 - 多言語対応: 海外の資料、論文、古い文献を扱うなら、必要な言語の文字やアクセント記号まで正しく認識できるか確認しましょう。130以上の言語に対応するLynoteのようなツールは、実務での使い勝手が高いです。
- 一括処理: スキャンした請求書のフォルダ全体や、複数の論文をまとめてPDF 文字起こししたいこともあります。複数ファイルを一度にアップロードし、順番に処理できるツールなら、1件ずつ対応するより大幅に時短できます。
- 柔軟な書き出し方法: 文字を抽出できても、それを使えなければ意味がありません。クリップボードにコピー、.txtや.docxでダウンロードなどがワンクリックでできるかを確認しましょう。最近のツールでは、同じ画面で文書とチャットしたり、抽出テキストをそのまま翻訳したりできるものもあります。
こうした機能を備えたツールを選べば、面倒なPDF処理も、調査や分析フローの一部としてスムーズに回せるようになります。
OCR結果が崩れたときの対処法
どれだけ優れたOCRでも、低品質なスキャン、手書きメモ、極端に複雑なレイアウトでは100%完璧とは限りません。抽出テキストが少し崩れていても大丈夫です。すぐ整えられる実用的なコツを紹介します。
- 段落の崩れを直す: 段組みのテキストが混ざると、だらだら続く長い行になりがちです。いちばん手早いのは、テキストをメモ帳やTextEditのようなシンプルなエディタに貼り付けて、必要な位置で手動で改行を入れ直すこと。1分ほどで、あなたにもChatGPTにも読みやすい形に整います。
- よくある誤認識は置換でまとめて修正: OCRには定番のミスがあります。
lの代わりに1、iの代わりに!が多いなら、エディタの「検索と置換」(Ctrl+H または Cmd+Shift+H)を使いましょう。数か所まとめて置換するだけで、数秒で大半のミスを片付けられます。 - 要約前に不要部分を削る: 整えたテキストをChatGPTに渡して要約させる前に、ヘッダー、フッター、ページ番号、図表キャプションなど不要な部分を削除しておくのがおすすめです。AIが本文に集中しやすくなり、より正確で簡潔な出力につながります。
最初に少しだけ整えておくだけで、あとから混乱する手間を減らせて、AI分析の結果もぐっと使いやすくなります。
よくある質問
ChatGPT-4oはスキャンPDFの文字を読めますか?
いいえ、直接は読めません。GPT-4oのような高性能モデルでも、通常のファイルアップロード機能には、ユーザー向けのOCRエンジンが標準搭載されていません。スキャンPDFや画像PDFをアップロードすると、同じように「テキストを抽出できませんでした」というエラーになることがあります。先に外部のPDF OCRツールでテキスト化し、その文字列をプロンプトに貼り付ける必要があります。
PDFから文字をコピーできるのに、なぜChatGPTでは読めないのですか?
これはPDFの見えない構造に関係する、とても重要なポイントです。多くのPDFには、見た目の画像レイヤーと、作成時に埋め込まれた不可視のテキストレイヤーの両方があります。あなたが範囲選択してコピーできるのは、Adobe AcrobatやPreviewのようなPDFビューアが、その隠れたテキストレイヤーを読んでいるからです。ですが、そのテキストレイヤーが壊れていたり、欠けていたり、文字コードが特殊だったりすると、ChatGPT側のシンプルな解析処理では読めず、ローカルのソフトではコピーできても失敗することがあります。
ChatGPTで読めるようにPDFを無料でテキスト化する方法はありますか?
はい。この記事で紹介した、Lynoteのようなツールの無料枠を使う方法は、かなり実用的です。基本的なPDFテキスト抽出であれば、支払い不要・アカウント登録なしで高品質なOCRを使えます。無料のオンラインOCRツールは他にもありますが、広告が多かったり、精度が低かったり、ファイルサイズ制限が厳しかったりすることが少なくありません。
抽出後に太字や斜体などの書式が消えるのはなぜですか?
文字抽出ツール、特に PDF OCR を使うタイプは、リッチテキストの書式ではなく、あくまで_文字そのもの_を取り出すことを優先します。そのため、出力結果はほとんどの場合プレーンテキストになります。これはAIモデルにとってはむしろ好都合で、重視するのは見た目の装飾ではなく、文章の意味や内容だからです。
結論:用途に合ったツールを使うのが最短です
ChatGPT は文章の要約や分析には非常に優れていますが、あらゆるファイル形式を万能に扱えるツールではありません。"no text could be extracted from this file" というエラーは不具合ではなく、できることの範囲を示しています。ChatGPT はテキストを処理するために作られており、スキャンPDFや画像PDF、複雑なレイアウトに埋もれた文字を読み取る用途には向いていません。
学生、研究者、ビジネス用途で多様な書類を扱う方にとって、答えはシンプルです。無理にChatGPTだけで読ませようとせず、PDF 文字抽出ツールを組み合わせること。 OCR対応の専用ツールをワークフローに加えれば、面倒だった作業は「先に PDF テキスト抽出、次に要約・分析」という安定した2ステップに変わります。時間を節約できるだけでなく、シンプルなPDFだけでなく、スキャンPDF テキスト化や画像PDF テキスト抽出が必要なファイルでも、AIを実用レベルで活用しやすくなります。

