
ChatGPT liest PDF nicht? Gründe und 3-Schritte-Lösung
Sie haben genau die richtige PDF vor sich – eine dichte wissenschaftliche Arbeit, einen eingescannten Kundenvertrag oder ein Kapitel aus einem Lehrbuch. Sie laden die Datei in ChatGPT hoch, wollen schnell eine Zusammenfassung oder Analyse erstellen, und dann kommt die Fehlermeldung: „Kein Text konnte aus dieser Datei extrahiert werden.“ Dieses Problem tritt erstaunlich oft auf und bringt den Arbeitsfluss sofort zum Stillstand. Wenn Sie diese Meldung gerade vor sich haben, sind Sie nicht allein – und es liegt nicht an Ihnen. Der eigentliche Grund ist, dass ChatGPT für solche PDF-Dateien nicht gemacht ist.

Das Kernproblem: ChatGPT ist ein Sprachmodell, aber kein universeller Dokumentenkonverter. Es verarbeitet sauberen, digitalen Text sehr gut. Viele PDFs – vor allem Scans oder komplex aufgebaute Berichte – bestehen jedoch im Grunde nur aus Text als Bild, nicht aus echtem, auslesbarem Text. ChatGPT hat keine integrierte OCR, um solche bildbasierten Dokumente zu „lesen“. Das ist, als würde man einen brillanten Sprachwissenschaftler ohne Sicht bitten, ein Foto von einer Buchseite zu beschreiben. In diesem Leitfaden erfahren Sie genau, warum dieser Fehler auftritt und wie Sie mit einer zuverlässigen 3-Schritte-Lösung den Text trotzdem aus der PDF extrahieren.
Kurzfazit: ChatGPT vs. PDF-Text-Extraktor mit OCR
Wenn es schnell gehen muss, ist die wichtigste Frage ganz einfach: Welche Art von PDF haben Sie? Ein normales, textbasiertes Dokument – oder eine schwierige Scan-PDF bzw. Bild-PDF?
Die folgende Tabelle zeigt, wann ChatGPT mit dem normalen Upload ausreicht – und wann ein spezialisiertes Tool die deutlich bessere Wahl ist.
| Funktion / Szenario | ChatGPT (normaler Upload) | OCR-Tool zur Texterkennung (z. B. Lynote) |
|---|---|---|
| Gescannte / bildbasierte PDF | Scheitert (Bewertung: 1/5) | Sehr gut (Bewertung: 5/5) |
| Mehrspaltige Layouts | Unzuverlässig; Text wird oft durcheinandergebracht | Gut; behält die Lesereihenfolge bei |
| Passwortgeschützte Dateien | Scheitert (Bewertung: 1/5) | Scheitert ebenfalls (aus Sicherheitsgründen) |
| Geschwindigkeit (bei sauberen PDFs) | Schnell bei kurzen, einfachen Dateien | Schnell; für größere Mengen optimiert |
| Am besten geeignet für | Analyse einfacher, digital erstellter PDFs (z. B. aus Microsoft Word exportiert) | Text aus Scans, Dokumentfotos oder komplexen Layouts extrahieren |
Die Bewertungen sind redaktionelle Einschätzungen (1=schwach, 5=sehr gut), keine gemessenen Benchmarks.
Die Schlussfolgerung ist einfach: Wurde Ihre PDF direkt in einem Textprogramm wie Microsoft Word oder Google Docs erstellt, kann ChatGPT sie möglicherweise verarbeiten. Bei allem anderen – besonders bei gescannten, fotografierten oder stark gestalteten Dokumenten – brauchen Sie ein Tool mit eigener OCR-Engine.
4 Hauptgründe, warum ChatGPT Ihre PDF nicht lesen kann
Vielleicht fragen Sie sich: „Wenn ich den Text auf dem Bildschirm sehen kann, warum kann ChatGPT das nicht?“ Die Antwort liegt im Aufbau von PDF-Dateien. Eine PDF ist nicht immer das, wonach sie aussieht. Hier sind die vier häufigsten Ursachen für den Fehler beim Text auslesen.
1. Bild-PDF oder gescannte PDF (der häufigste Grund)
Das ist mit Abstand die häufigste Ursache. Wenn Sie ein Papierdokument scannen oder eine Datei als „Bild-PDF“ speichern, wird kein echter Text gespeichert. Stattdessen speichern Sie ein Foto der Seite. Für den Computer unterscheiden sich die Buchstaben in dieser Datei nicht von den Pixeln in einem Bild von einem Baum.
- Das typische Szenario: Sie sind Student und möchten einen 30-seitigen Fachartikel analysieren, den Ihr Dozent aus einem Bibliotheksbuch eingescannt hat. Sie laden die Datei hoch – und ChatGPT erkennt nur eine Sammlung von Bildern.
- Die technische Hürde: Ohne OCR (Optical Character Recognition), also Texterkennung, die Zeichen in Bildern erkennt und in digitalen Text umwandelt, bleibt der Inhalt für ChatGPT unsichtbar. Es braucht eine echte Textebene – und genau die fehlt bei gescannten PDFs.
2. Komplexe Layouts und Formatierungen
PDFs sind ideal, um visuelle Gestaltung zu erhalten – etwa Spalten, Tabellen, Kopf- und Fußzeilen oder frei platzierte Bilder. Genau das macht die Textextraktion aber schwierig. Der integrierte Parser von ChatGPT ist eher einfach aufgebaut und erwartet einen klaren, linearen Textfluss.
- Das typische Szenario: Sie arbeiten als Business-Analyst mit einem Marktforschungsbericht voller zweispaltigem Text, Diagrammen mit Beschriftungen und Datentabellen. Wenn ChatGPT versucht, die Datei zu lesen, werden die Spalten vermischt – und aus sinnvollen Sätzen wird unverständlicher Text.
Das Wachstum des Unternehmens im dritten Quartal war das Ergebnis des neuen Marketings ... bemerkenswert, mit 5 Millionen Einheiten ... einer Strategie mit Fokus auf soziale Medien. - Die technische Hürde: Der Parser erkennt nicht zuverlässig, ob etwas ein Spaltenumbruch oder das Ende eines Absatzes ist. Er liest nach Position auf der Seite statt nach logischem Lesefluss – und genau dadurch entsteht ein Textchaos.
3. Passwortgeschützte oder verschlüsselte Dateien
Dieser Fall ist einfacher zu erklären. Wenn eine PDF ein Passwort zum Öffnen benötigt oder das Kopieren von Text eingeschränkt ist, respektiert ChatGPT diese Sicherheitseinstellungen. Es wird nicht versuchen, sie zu umgehen – und kann es auch nicht.
- Das typische Szenario: Ein Kollege schickt Ihnen per E-Mail einen sensiblen, passwortgeschützten Finanzbericht zur Analyse. Sie können die Datei nicht einfach hochladen und erwarten, dass ChatGPT sie öffnet.
- Die technische Hürde: Der Inhalt der Datei ist verschlüsselt. Erst wenn sie mit dem richtigen Passwort entsperrt wird, sind die Daten für Anwendungen lesbar – auch für KI-Modelle.
4. Beschädigte Datei oder nicht standardisierte Kodierung
Seltener, aber durchaus möglich: Die PDF-Datei selbst ist beschädigt oder verwendet eine ungewöhnliche Textkodierung, die der Parser von ChatGPT nicht erkennt. Das kann nach einem fehlerhaften Download, einer misslungenen Dateikonvertierung oder bei sehr alten Dokumenten passieren. Die Textebene kann technisch vorhanden sein, ist aber so fehlerhaft gespeichert, dass sie nicht ausgelesen werden kann.
Kurz gesagt: Ein spezialisiertes Tool ist bei der PDF-Textextraktion ChatGPT vor allem deshalb überlegen, weil es eine integrierte OCR-Engine hat, die Text in Bildern zuverlässig in maschinenlesbare Zeichen umwandelt, mit denen eine KI weiterarbeiten kann.
Die Lösung: In 3 Schritten Text aus jeder PDF extrahieren
Wenn ChatGPT scheitert, verschwenden Sie keine Zeit mit immer neuen Prompts oder dem erneuten Hochladen derselben Datei. Die bessere Lösung ist, die PDF vorher mit einem dafür entwickelten Tool zu verarbeiten. Ein KI-gestütztes Tool zur Transkription und Datenextraktion mit starker OCR-Engine ist der zuverlässigste Weg, um Text aus PDF zu extrahieren.
So geht es in unter einer Minute mit einem Tool wie Lynote KI-Transkription, das in der Basisversion kostenlos ist und ohne Konto gestartet werden kann.
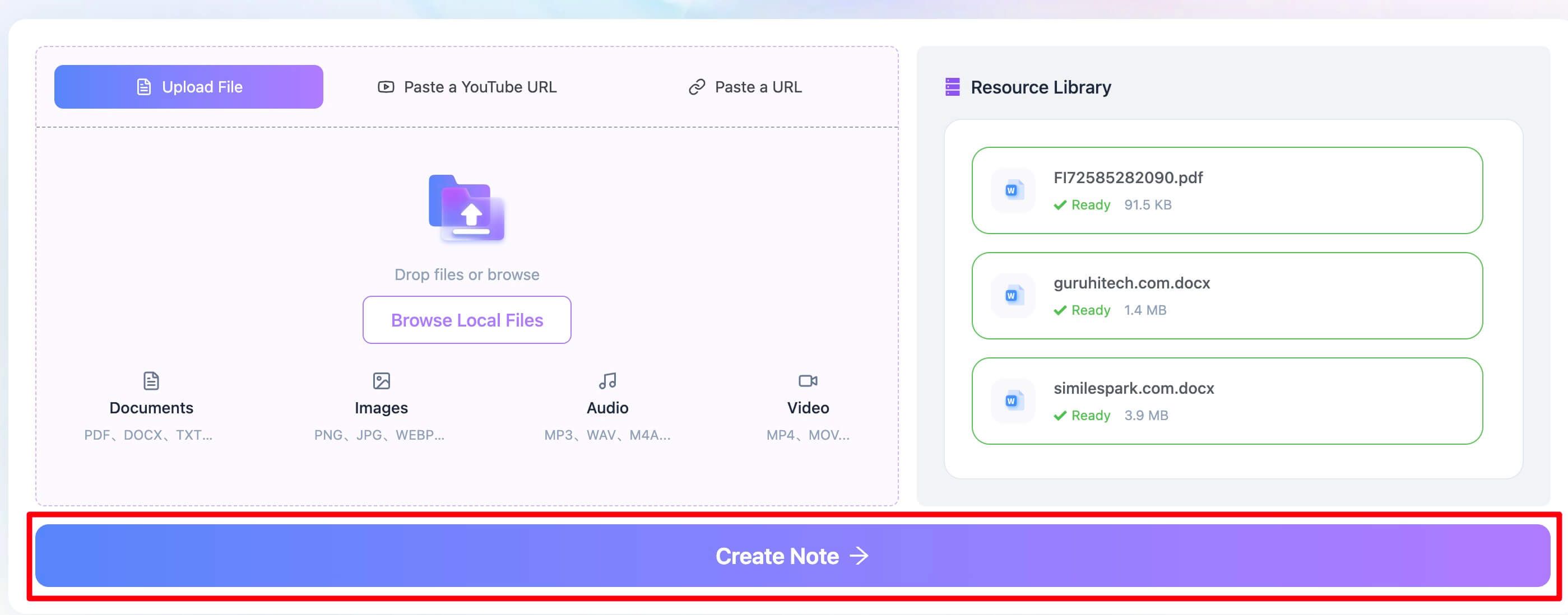
Schritt 1: Problematische PDF hochladen
Öffnen Sie zuerst den PDF-Text-Extractor von Lynote. Statt die Datei in ChatGPT hochzuladen, ziehen Sie die problematische PDF direkt in den Upload-Bereich von Lynote. Alternativ können Sie auf Ihrem Computer nach der Datei suchen und sie auswählen. Das funktioniert besonders gut bei gescannten Vorlesungsunterlagen, komplexen Berichten oder bildbasierten Dokumenten, die ChatGPT sofort ablehnt.

Schritt 2: Text aus der PDF extrahieren
Sobald die Datei hochgeladen ist, klicken Sie einfach auf die Schaltfläche „Create Note“. Das ist der entscheidende Schritt. Im Hintergrund legt Lynote sofort los und wendet eine leistungsstarke OCR-Engine auf Ihr Dokument an. Dabei wird nicht nur nach einer vorhandenen Textebene gesucht: Die Seite wird als Bild analysiert, Zeichen werden erkannt und der Text digital neu aufgebaut. Unterstützt werden mehr als 130 Sprachen – ideal also auch für internationale Dokumente.
Schritt 3: PDF-Text prüfen und kopieren
Schon nach wenigen Sekunden erscheint der sauber extrahierte Text in einem Online-Editor. Damit haben Sie jetzt eine textbasierte Quelle, die ChatGPT problemlos versteht. Prüfen Sie den Inhalt kurz auf offensichtliche OCR-Fehler, nehmen Sie bei Bedarf kleine Korrekturen vor und kopieren Sie dann den gesamten Text. Anschließend fügen Sie ihn direkt in Ihren ChatGPT-Prompt ein und machen mit Analyse, Zusammenfassung oder Frage weiter. Auf Wunsch können Sie den Text auch als .txt-Datei herunterladen und später verwenden.

Mit diesem 3-Schritte-Prozess überbrücken Sie zuverlässig die Lücke zwischen einer bildbasierten PDF und der textbasierten Arbeitsweise von ChatGPT.

Worauf Sie bei einem Tool zur PDF-Textextraktion achten sollten
Sobald klar ist, dass Sie ein spezialisiertes Tool brauchen, stoßen Sie schnell auf viele Optionen. Aber woran erkennt man ein wirklich gutes Tool? Hier sind die wichtigsten Funktionen, auf die Sie achten sollten – besonders dann, wenn Sie regelmäßig Dokumente verarbeiten.
- Hohe OCR-Genauigkeit: Darauf kommt es an. Die wichtigste Aufgabe des Tools ist es, Bilder präzise in Text umzuwandeln. Eine gute Engine minimiert Fehler (zum Beispiel wenn
lmit1oderrnmitmverwechselt wird) und kommt mit unterschiedlichen Schriftarten und Auflösungen zurecht. - Unterstützung für viele Sprachen: Wenn Sie mit internationalen Dokumenten, wissenschaftlichen Arbeiten oder historischen Texten arbeiten, sollte das Tool die benötigten Zeichen, Sonderzeichen und Akzente zuverlässig erkennen. Tools wie Lynote mit Unterstützung für über 130 Sprachen bieten hier wichtige Flexibilität.
- Stapelverarbeitung: Möchten Sie Text aus einem ganzen Ordner mit gescannten Rechnungen oder aus einem Dutzend Fachartikeln auslesen? Ein Tool, mit dem Sie mehrere Dateien gleichzeitig hochladen und in einer Warteschlange verarbeiten können, spart enorm viel Zeit gegenüber der Einzelbearbeitung.
- Flexible Exportoptionen: Den Text zu extrahieren ist nur die halbe Arbeit – Sie müssen ihn auch weiterverwenden können. Achten Sie auf einfache Optionen per Klick, um den Text in die Zwischenablage zu kopieren, als
.txt- oder.docx-Datei herunterzuladen oder direkt weiterzuverarbeiten. Moderne Tools erlauben oft auch, mit dem Dokument zu chatten oder den extrahierten Text in derselben Oberfläche zu übersetzen.
Ein Tool mit diesen Funktionen macht aus einem frustrierenden Hindernis einen reibungslosen Teil Ihres Recherche- und Analyse-Workflows.
Profi-Tipp: Unsauberen oder fehlerhaften PDF-Text schnell bereinigen
Selbst die beste OCR-Technologie ist nicht in jedem Fall perfekt – vor allem bei Scans mit schlechter Qualität, handschriftlichen Notizen oder sehr komplexen Layouts. Wenn der extrahierte Text etwas chaotisch aussieht, ist das kein Grund zur Sorge. Mit diesen einfachen Profi-Tricks bekommen Sie ihn schnell in Form.
- Kaputte Absätze korrigieren: Wenn Text aus mehreren Spalten zusammengezogen wurde, entstehen oft lange, schwer lesbare Zeilen. Am schnellsten beheben Sie das, indem Sie den Text in einen einfachen Editor wie Notepad oder TextEdit einfügen und mit „Enter“ die Absatzumbrüche manuell wiederherstellen. Das dauert nur kurz, macht den Text aber für Sie und für ChatGPT deutlich besser lesbar.
- Typische OCR-Fehler per Suchen und Ersetzen beheben: OCR macht oft klassische Fehler. Wenn zum Beispiel häufig
1stattloder!stattiauftaucht, nutzen Sie die Funktion „Suchen und Ersetzen“ Ihres Editors (Strg+H oder Cmd+Shift+H). Mit ein paar gezielten Ersetzungen lassen sich in Sekunden viele Fehler bereinigen. - Vor dem Zusammenfassen vereinfachen: Bevor Sie den bereinigten Text für eine Zusammenfassung an ChatGPT geben, entfernen Sie am besten irrelevante Bereiche wie Kopfzeilen, Fußzeilen, Seitenzahlen oder Bildunterschriften. So konzentriert sich die KI auf den eigentlichen Inhalt – und die Ausgabe wird oft präziser und knapper.
Ein wenig Bereinigung am Anfang erspart später viel Verwirrung und sorgt meist für deutlich bessere Ergebnisse bei der KI-Analyse.
Häufige Fragen
Kann ChatGPT-4o Text aus einer gescannten PDF lesen?
Nein, nicht direkt. Selbst fortschrittlichere Modelle wie GPT-4o haben in der normalen Datei-Upload-Funktion keine integrierte, für Nutzer zugängliche OCR-Engine. Wenn Sie eine gescannte oder rein bildbasierte PDF hochladen, erhalten Sie denselben Fehler: „kein Text konnte aus dieser Datei extrahiert werden“. Sie müssen die PDF also zuerst mit einem externen OCR-Tool in Text umwandeln und diesen Text anschließend in Ihren Prompt einfügen.
Warum funktioniert Kopieren aus meiner PDF, aber ChatGPT scheitert?
Das ist eine sehr gute Frage und zeigt, wie viele Ebenen in einer PDF stecken können. Viele PDFs enthalten sowohl eine Bildebene – also das, was Sie sehen – als auch eine unsichtbare Textebene, die beim Erstellen der Datei erzeugt wurde. Wenn Sie Text markieren und kopieren, greift Ihr PDF-Reader (zum Beispiel Adobe Acrobat oder Vorschau) auf diese versteckte Textebene zu. Ist diese Textebene jedoch beschädigt, unvollständig oder fehlerhaft kodiert, kann der einfachere serverseitige Parser von ChatGPT sie nicht zuverlässig lesen – auch wenn Ihre lokale Software damit klarkommt.
Gibt es eine kostenlose Möglichkeit, meine PDF für ChatGPT lesbar zu machen?
Ja. Die in diesem Artikel beschriebene Methode mit der kostenlosen Version eines Tools wie Lynote gehört zu den effektivsten Gratis-Optionen. Sie nutzt eine hochwertige OCR-Engine, ohne dass Sie für einfache Extraktionen bezahlen oder ein Konto anlegen müssen. Andere kostenlose OCR-Tools online gibt es zwar auch, sie sind aber oft voller Werbung, liefern ungenaue Ergebnisse oder setzen sehr enge Dateigrößenlimits.
Warum ist die Formatierung (fett, kursiv) nach dem Extrahieren verschwunden?
Tools zum Extrahieren von Text aus PDF-Dateien – besonders OCR-basierte – konzentrieren sich darauf, die Zeichen zu erfassen, nicht die Rich-Text-Formatierung. Das Ergebnis ist fast immer reiner Text. Für KI-Modelle ist das in der Regel sogar besser, weil sie vor allem den inhaltlichen Sinn verarbeiten und nicht die visuelle Gestaltung.
Fazit: Für PDFs das passende Tool nutzen
ChatGPT ist ein starkes Werkzeug für die Arbeit mit Sprache, aber kein Universalwerkzeug für jedes Dateiformat. Die Meldung „kein Text konnte aus dieser Datei extrahiert werden“ ist kein Bug, sondern eine technische Grenze. Das Modell ist dafür gemacht, sauberen digitalen Text zu verarbeiten – nicht Text aus Scans, Bild-PDFs oder komplexen Layouts zu entschlüsseln.
Für Studierende, Forschende und Berufstätige, die regelmäßig mit unterschiedlichen Dokumenten arbeiten, ist die Schlussfolgerung klar: Nicht gegen das Tool arbeiten, sondern den Workflow sinnvoll ergänzen. Wenn du einen speziellen PDF-Text-Extractor mit OCR in deinen Ablauf einbaust, wird aus einem ständigen Problem ein verlässlicher Prozess in zwei Schritten: erst Text aus PDF extrahieren, dann in ChatGPT zusammenfassen oder analysieren. Das spart Zeit und hilft dir, auch Text aus gescannter PDF, Bild-PDFs oder Dateien mit schwierigem Layout zuverlässig auszulesen – nicht nur aus einfachen PDFs.

