
ChatGPT no puede leer un PDF? La causa real y cómo arreglarlo en 3 pasos
Tienes justo el PDF que necesitas: un artículo académico denso, un contrato de cliente escaneado o un capítulo de un libro. Lo subes a ChatGPT para pedirle un resumen o un análisis y, de repente, te topas con el muro: «No se pudo extraer texto de este archivo». Es un bloqueo muy habitual y desesperante, porque corta el flujo de trabajo en seco. Si llevas un rato viendo ese mensaje, no eres el único. Y no es que estés haciendo algo mal: el problema está en una limitación básica de lo que ChatGPT puede hacer con ciertos PDF.

El problema de fondo es simple: ChatGPT es un modelo de lenguaje, no un conversor universal de documentos. Funciona muy bien cuando recibe texto digital limpio. Pero muchos PDF, sobre todo los escaneados o los informes con maquetación compleja, en realidad son imágenes de texto, no texto editable. Y ahí es donde falla: ChatGPT no incorpora de forma fiable el Reconocimiento Óptico de Caracteres (OCR) necesario para “leer” este tipo de archivos. Es como pedirle a un lingüista brillante que describa la foto de una página de un libro sin poder verla. En esta guía te explicamos por qué pasa este error y cómo solucionarlo con un método práctico de 3 pasos para sacar texto de un PDF sin perder tiempo.
Veredicto rápido: ChatGPT vs. extractor de texto de PDF con OCR
Si vas con prisa, aquí tienes la conclusión rápida. La forma de extraer texto de PDF depende por completo del tipo de archivo que tengas. ¿Es un documento sencillo con texto real o un PDF escaneado más problemático?
Esta tabla resume la diferencia entre pelearte con las funciones nativas de ChatGPT y usar una herramienta creada específicamente para OCR PDF online.
| Función / escenario | ChatGPT (subida nativa) | Extractor OCR especializado (p. ej., Lynote) |
|---|---|---|
| PDF escaneado o solo imagen | Falla (Puntuación: 1/5) | Excelente (Puntuación: 5/5) |
| Diseños con varias columnas | Irregular; a menudo mezcla el texto | Bueno; respeta el orden de lectura |
| Archivos protegidos con contraseña | Falla (Puntuación: 1/5) | Falla (por diseño, por seguridad) |
| Velocidad (en PDF limpios) | Rápido en archivos cortos y simples | Rápido; optimizado para lotes grandes |
| Mejor caso de uso | Analizar PDF simples creados digitalmente (por ejemplo, documentos exportados desde Word) | Extraer texto de PDF escaneado, fotos de documentos o archivos con maquetación compleja |
Las puntuaciones son una referencia editorial (1 = malo, 5 = excelente), no pruebas de rendimiento medidas.
La idea clave es esta: si tu PDF se creó directamente desde un editor de texto como Microsoft Word o Google Docs, puede que ChatGPT lo procese bien. Para casi todo lo demás —especialmente si el documento está escaneado, fotografiado o muy maquetado— necesitas una herramienta con un motor OCR específico.
4 motivos por los que ChatGPT no puede leer tu PDF
Puede que te estés preguntando: «Si yo veo el texto en pantalla, ¿por qué ChatGPT no puede?». La respuesta está en cómo se construyen los PDF. Un PDF no siempre es lo que parece. Estos son los cuatro motivos más habituales detrás del temido error al extraer texto.
1. PDF escaneado o PDF de solo imagen (el caso más común)
Este es, con diferencia, el motivo más frecuente. Cuando escaneas un documento en papel o guardas un archivo como PDF de imagen, no estás guardando texto real. Estás guardando una fotografía de la página. Para un ordenador, las letras de ese archivo no son más que píxeles, igual que en una foto de un árbol.
- El caso típico: eres estudiante y quieres analizar un artículo de 30 páginas que tu profesor escaneó de un libro de biblioteca. Lo subes y ChatGPT no ve más que un conjunto de imágenes.
- El problema técnico: sin Reconocimiento Óptico de Caracteres (OCR), que es el proceso que analiza imágenes e identifica letras para convertirlas en texto digital, ChatGPT no puede interpretar el contenido. Necesita una “capa” de texto para leer el archivo, y los PDF escaneados no la tienen.
2. Maquetación y formato complejos
Los PDF son muy buenos para conservar el diseño visual: columnas, tablas, encabezados, pies de página e imágenes flotantes. Pero esa ventaja también complica la extracción de texto. El analizador interno de ChatGPT es básico y espera un flujo de texto lineal y sencillo.
- El caso típico: eres analista de negocio y tienes un informe de mercado con texto a dos columnas, gráficos con anotaciones y tablas de datos. Cuando ChatGPT intenta leerlo, mezcla el contenido de las columnas y convierte frases coherentes en un galimatías.
The company's growth in Q3 was a result of the new marketing... remarkable, reaching 5 million units... strategy that focused on social media. - El problema técnico: el analizador no distingue bien entre un salto de columna y el final de un párrafo. Lee el texto según su posición en la página, no según su secuencia lógica, y por eso el resultado acaba desordenado.
3. Archivos protegidos con contraseña o cifrados
Aquí la explicación es más directa. Si un PDF necesita contraseña para abrirse o tiene restricciones para copiar texto, ChatGPT respetará esa configuración de seguridad. No va a intentar saltársela, ni puede hacerlo.
- El caso típico: un compañero te envía por correo un informe financiero sensible protegido con contraseña para que lo analices. No puedes subirlo sin más y esperar que ChatGPT lo abra.
- El problema técnico: el contenido del archivo está cifrado. Hasta que no se desbloquea con la contraseña correcta, los datos son ilegibles para cualquier aplicación, incluidos los modelos de IA.
4. Archivo dañado o codificación no estándar
Es menos habitual, pero también puede pasar: el propio PDF puede estar dañado o usar una codificación de texto poco común que el analizador de ChatGPT no reconoce. Esto puede ocurrir tras una descarga defectuosa, una conversión fallida o al trabajar con documentos muy antiguos. Puede que la capa de texto exista técnicamente, pero esté desordenada de una forma que impide acceder a ella.
En resumen: la principal razón por la que una herramienta especializada supera a ChatGPT al extraer texto de PDF es su motor OCR integrado, diseñado específicamente para convertir imágenes con texto en caracteres legibles por máquina que una IA sí puede entender.
La solución: cómo extraer texto de cualquier PDF en 3 pasos
Cuando ChatGPT falla, no pierdas tiempo probando prompts distintos ni subiendo el mismo archivo una y otra vez. La forma más rápida de arreglarlo es preprocesar el PDF con una herramienta pensada para eso. Usar una solución de transcripción y extracción de datos con IA, con un motor OCR potente, es la manera más fiable de sacar texto de un PDF.
Así puedes hacerlo en menos de un minuto con una herramienta como Transcripción con IA de Lynote, gratuita para un uso básico y sin necesidad de crear una cuenta para empezar.
Paso 1. Sube el PDF que da problemas
Primero, entra en el extractor de texto de PDF de Lynote. En lugar de subir el archivo a ChatGPT, arrastra y suelta el PDF problemático directamente en el área de carga de Lynote. También puedes hacer clic para buscarlo en tu ordenador y seleccionarlo manualmente. Esto va especialmente bien si necesitas extraer texto de PDF escaneado, apuntes escaneados, informes con maquetación compleja o documentos basados en imágenes que ChatGPT rechaza al instante.

Paso 2. Extrae el texto del PDF
Una vez subido el archivo, solo tienes que hacer clic en el botón "Create Note". Este es el paso clave. El sistema de Lynote se pone a trabajar de inmediato y aplica un potente motor OCR al documento. No se limita a buscar una capa de texto ya existente: analiza cada página como imagen, identifica los caracteres y reconstruye el texto en formato digital. Es compatible con más de 130 idiomas, así que también funciona muy bien con documentos internacionales.
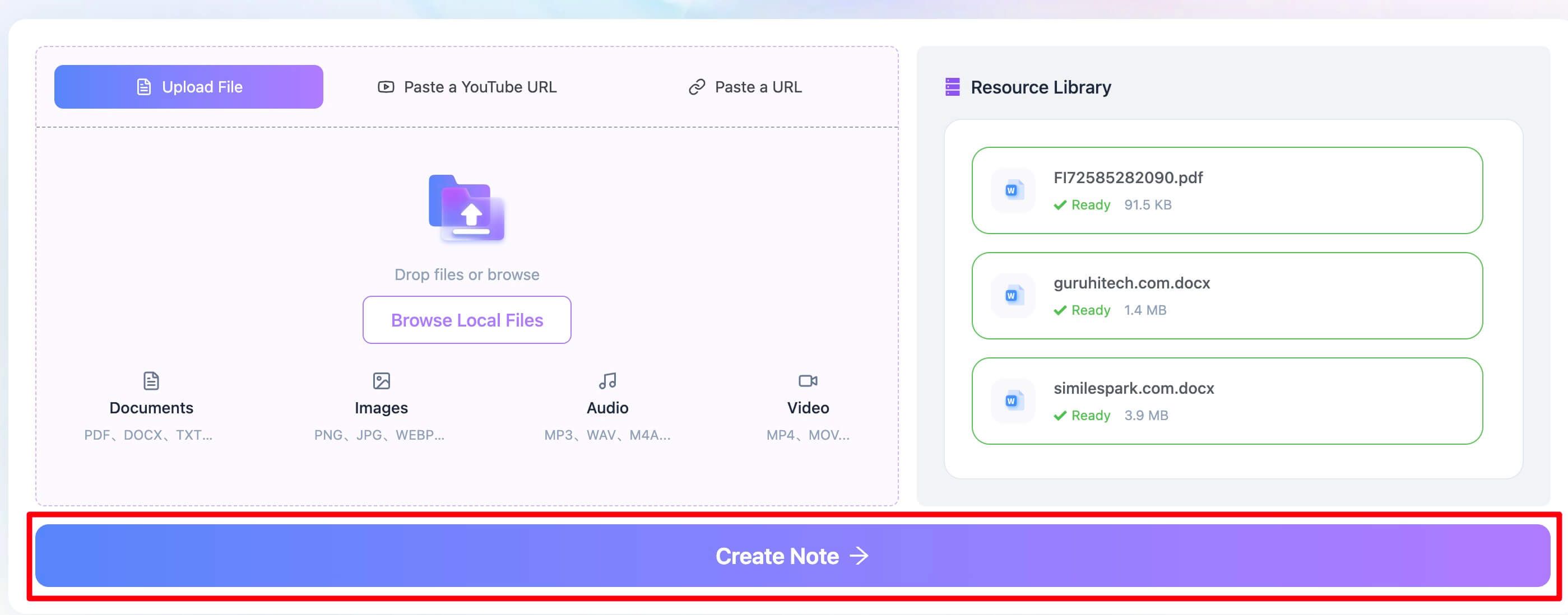
Paso 3. Revisa y copia el texto extraído
En cuestión de segundos verás el texto limpio en un editor online. Ahora ya tienes una fuente en texto editable que ChatGPT sí puede entender sin problemas. Puedes revisarla rápidamente para detectar errores evidentes del OCR, hacer pequeños ajustes y copiar todo el contenido de una vez. Después, solo tienes que pegarlo directamente en tu prompt de ChatGPT y seguir con tu análisis, resumen o consulta. También puedes descargar el texto como archivo .txt para usarlo más tarde.

Este proceso de tres pasos resuelve el problema entre un PDF basado en imágenes y el entorno de texto que ChatGPT necesita para trabajar.

Más allá del arreglo: qué buscar en una herramienta para extraer texto de PDF
Cuando ves que necesitas una herramienta específica, enseguida aparecen muchas opciones. Entonces, ¿qué diferencia una buena de una mediocre? Estas son las funciones clave en las que deberías fijarte, sobre todo si trabajas con documentos con frecuencia.
- OCR de alta precisión: Esto es imprescindible. La función principal de la herramienta es convertir imágenes en texto con precisión. Un buen motor reduce errores (como confundir
lcon1ornconm) y maneja bien distintos tipos de letra y resoluciones. - Compatibilidad con varios idiomas: Si trabajas con documentos internacionales, artículos académicos o textos históricos, asegúrate de que la herramienta pueda reconocer los caracteres y signos diacríticos de los idiomas que necesitas. Herramientas como Lynote, con soporte para más de 130 idiomas, ofrecen una flexibilidad muy útil.
- Procesamiento por lotes: ¿Necesitas convertir PDF escaneado a texto de toda una carpeta de facturas o de una docena de artículos? Una herramienta que permita subir varios archivos a la vez y procesarlos en cola ahorra muchísimo tiempo frente a hacerlo uno por uno.
- Opciones de exportación flexibles: Extraer el texto es solo la mitad del trabajo. Luego hay que poder usarlo. Busca opciones sencillas para copiar al portapapeles, descargar como archivo .txt o .docx o seguir trabajando con él. Las herramientas modernas también pueden permitirte chatear con el documento o traducir el texto extraído dentro de la misma interfaz.
Elegir una herramienta con estas funciones convierte un bloqueo frustrante en una parte fluida de tu proceso de investigación y análisis.
Consejo práctico: cómo tratar texto extraído desordenado o inexacto
Ni siquiera la mejor tecnología OCR acierta el 100 % de las veces, especialmente con escaneos de baja calidad, notas manuscritas o diseños muy complejos. Si al extraer texto de PDF el resultado sale algo desordenado, no pasa nada. Aquí tienes algunos trucos profesionales para limpiarlo rápido.
- Corrige los párrafos rotos: Si el texto de varias columnas se ha mezclado, verás líneas larguísimas y difíciles de leer. La forma más rápida de arreglarlo es pegar el texto en un editor sencillo (como Bloc de notas o TextEdit) y pulsar "Enter" manualmente para recuperar los saltos de párrafo. Lleva un minuto, pero hace que el texto sea mucho más legible tanto para ti como para ChatGPT.
- Usa Buscar y reemplazar para errores frecuentes: El OCR suele cometer fallos típicos. Si ves muchos
1donde debería haberl, o!en lugar dei, usa la función "Buscar y reemplazar" de tu editor de texto (Ctrl+H o Cmd+Shift+H). Con unos pocos reemplazos bien pensados puedes corregir el 90 % de los errores en segundos. - Simplifica antes de resumir: Antes de pegar el texto limpio en ChatGPT para pedir un resumen, plantéate eliminar partes irrelevantes como encabezados, pies de página, números de página y leyendas de figuras. Así la IA se centra en el contenido principal y normalmente devuelve un resultado más preciso y más claro.
Dedicar un poco de tiempo a limpiar el texto al principio puede ahorrarte mucha confusión después y dar mejores resultados en tu análisis con IA.
Preguntas frecuentes
¿ChatGPT-4o puede leer texto de un PDF escaneado?
No, no directamente. Incluso los modelos más avanzados como GPT-4o siguen sin ofrecer un motor OCR integrado y accesible para el usuario en la función estándar de subida de archivos. Si subes un PDF escaneado o un PDF compuesto solo por imágenes, recibirás el mismo error de "no se pudo extraer texto de este archivo". Primero necesitas usar una herramienta OCR externa para pasar el PDF a texto editable y después pegar ese texto en tu prompt.
¿Por qué puedo copiar y pegar desde mi PDF, pero ChatGPT falla?
Es una muy buena pregunta y revela las capas ocultas de un PDF. Muchos archivos PDF tienen tanto una capa de imagen (lo que ves) como una capa de texto invisible (generada al crear el archivo). Cuando seleccionas y copias, tu lector de PDF —como Adobe Acrobat o Preview— toma el contenido de esa capa de texto oculta. Pero si esa capa está dañada, falta o tiene una codificación deficiente, el analizador más simple que usa ChatGPT en el servidor no puede leerla, aunque tu programa local sí lo consiga.
¿Hay alguna forma gratis de hacer que ChatGPT pueda leer el texto de mi PDF?
Sí. El método que explicamos en este artículo, usando el plan gratuito de una herramienta como Lynote, es una de las opciones gratis más eficaces. Utiliza un motor OCR de alta calidad sin exigir pago ni cuenta para extracciones básicas. Aunque existen otras opciones de OCR PDF online, muchas están llenas de anuncios, tienen poca precisión o imponen límites de tamaño de archivo demasiado restrictivos.
¿Por qué desapareció el formato (negrita, cursiva) al extraer el texto?
Las herramientas para extraer texto, especialmente las basadas en OCR, están pensadas para captar los caracteres, no el formato enriquecido del documento. Por eso, el resultado casi siempre se entrega como texto plano. En general, esto es incluso mejor para los modelos de IA, ya que se centran sobre todo en el contenido semántico y no en el estilo visual.
Conclusión: usa la herramienta adecuada
ChatGPT es una herramienta revolucionaria para trabajar con lenguaje, pero no es una navaja suiza para cualquier formato de archivo. El error "no se pudo extraer texto de este archivo" no es un fallo: marca un límite de lo que puede hacer. El modelo está diseñado para procesar texto limpio y digital, no para interpretar imágenes de texto atrapadas en PDFs escaneados o maquetaciones complejas.
Para estudiantes, investigadores y profesionales que trabajan a menudo con documentos muy distintos, la conclusión es clara: no intentes forzar la herramienta; complétala con la adecuada. Si añades a tu flujo de trabajo un extractor de texto de PDF con OCR, conviertes una frustración recurrente en un proceso fiable de dos pasos: primero extraer, después analizar. Así no solo ahorras tiempo, sino que también aprovechas de verdad todo el potencial de la IA en cualquier PDF, no solo en los más simples.

