
Kan ChatGPT geen tekst uit PDF extraheren? Dit is de echte reden en een oplossing in 3 stappen
Je hebt de perfecte PDF – een dicht academisch artikel, een gescand klantencontract of een hoofdstuk uit een studieboek. Je uploadt het naar ChatGPT, klaar voor een samenvatting of analyse, en dan loop je tegen een muur: “Geen tekst kon uit dit bestand worden geëxtraheerd.” Het is een frustrerend veelvoorkomende hindernis die je workflow volledig stillegt. Als je naar deze foutmelding hebt gestaard, ben je niet de enige, en het probleem ligt niet bij jou – het is een fundamenteel misverstand over waarvoor ChatGPT is gebouwd.

Het kernprobleem is dat ChatGPT een taalmodel is, geen universele documentconverter. Het blinkt uit in het verwerken van schone, digitale tekst. Veel PDF's, vooral scans of complexe rapporten, zijn echter in wezen afbeeldingen van tekst, niet de tekst zelf. ChatGPT mist de ingebouwde Optische Tekenherkenning (OCR) die nodig is om deze op afbeeldingen gebaseerde documenten te 'lezen'. Het is alsof je een briljante linguïst die niet kan zien vraagt om een foto van een boekpagina te beschrijven. Deze gids legt precies uit waarom deze fout optreedt en geeft je een betrouwbare oplossing in drie stappen om de tekst te krijgen die je nodig hebt.
Snel oordeel: ChatGPT versus een speciale PDF-tekstextractor
Voor degenen met een deadline, hier is de kern van de zaak. Je methode om tekst uit een PDF te halen, hangt volledig af van het type PDF dat je hebt. Is het een eenvoudig, tekstgebaseerd document of een lastige, gescande afbeelding?
Deze tabel splitst de keuze op tussen worstelen met de native mogelijkheden van ChatGPT en het gebruik van een speciaal gebouwd hulpmiddel.
| Functie / Scenario | ChatGPT (Native Upload) | Speciale OCR-extractor (bijv. Lynote) |
|---|---|---|
| Gescande/Alleen-afbeelding PDF | Faalt (Score: 1/5) | Uitstekend (Score: 5/5) |
| Lay-outs met meerdere kolommen | Wisselvallig; vaak wordt tekst door elkaar gegooid | Goed; behoudt leesvolgorde |
| Met wachtwoord beveiligde bestanden | Faalt (Score: 1/5) | Faalt (uit veiligheidsoverwegingen) |
| Snelheid (voor schone PDF's) | Snel voor korte, eenvoudige bestanden | Snel; geoptimaliseerd voor grote batches |
| Beste gebruiksscenario | Analyseren van eenvoudige, digitaal gemaakte PDF's (bijv. geëxporteerde Word-documenten) | Tekst extraheren uit scans, foto's van documenten of complexe lay-outs |
Scores zijn redactionele heuristieken (1=Slecht, 5=Uitstekend), geen gemeten benchmarks.
De conclusie is eenvoudig: als je PDF rechtstreeks is gemaakt vanuit een teksteditor (zoals Microsoft Word of Google Docs), kan ChatGPT het misschien verwerken. Voor al het andere – vooral documenten die zijn gescand, gefotografeerd of zwaar zijn ontworpen – heb je een tool nodig met een speciale OCR-engine.
De 4 belangrijkste redenen waarom ChatGPT je PDF niet kan lezen
Je vraagt je misschien af: "Als ik de tekst op mijn scherm kan zien, waarom kan ChatGPT dat dan niet?" Het antwoord ligt in de manier waarop PDF's zijn opgebouwd. Een PDF is niet altijd wat het lijkt. Hier zijn de vier belangrijkste boosdoeners achter die gevreesde extractiefout.
1. Alleen-afbeelding of gescande PDF's (De grootste boosdoener)
Dit is verreweg de meest voorkomende reden voor falen. Wanneer je een fysiek document scant of een bestand opslaat als een "afbeelding-PDF", sla je geen tekst op. Je slaat een foto van de pagina op. Voor een computer zijn de letters in dat bestand niet anders dan de pixels in een foto van een boom.
- Het scenario: Je bent een student die een 30 pagina's tellend tijdschriftartikel probeert te analyseren dat je professor uit een bibliotheekboek heeft gescand. Je uploadt het, en ChatGPT ziet niets anders dan een verzameling afbeeldingen.
- De technische hindernis: Zonder Optische Tekenherkenning (OCR), een proces dat afbeeldingen analyseert om tekens te identificeren en om te zetten in digitale tekst, is ChatGPT blind voor de inhoud. Het heeft een tekst-'laag' nodig om te lezen, en gescande PDF's hebben die niet.
2. Complexe lay-outs en opmaak
PDF's zijn geweldig voor het behouden van visueel ontwerp – kolommen, tabellen, kopteksten, voetteksten en zwevende afbeeldingen. Deze kracht is ook een zwakte voor tekstextractie. De ingebouwde parser van ChatGPT is basic; het verwacht een eenvoudige, lineaire tekststroom.
- Het scenario: Je bent een bedrijfsanalist met een marktonderzoeksrapport vol tekst in twee kolommen, grafieken met toelichtingen en gegevenstabellen. Wanneer ChatGPT het probeert te lezen, wordt de tekst uit de kolommen door elkaar gehaald, waardoor coherente zinnen onzin worden.
The company's growth in Q3 was a result of the new marketing... remarkable, reaching 5 million units... strategy that focused on social media. - De technische hindernis: De parser kan geen onderscheid maken tussen een kolomovergang en het einde van een paragraaf. Het leest tekst op basis van de positie op de pagina, niet de logische stroom, wat resulteert in een verwarde puinhoop.
3. Met wachtwoord beveiligde of versleutelde bestanden
Deze is eenvoudiger. Als een PDF een wachtwoord vereist om te openen of beperkingen heeft op het kopiëren van tekst, zal ChatGPT die beveiligingsinstellingen respecteren. Het zal (en kan) ze niet proberen te omzeilen.
- Het scenario: Een collega e-mailt je een gevoelig, met wachtwoord beveiligd financieel rapport voor analyse. Je kunt het niet zomaar uploaden en verwachten dat ChatGPT het kraakt.
- De technische hindernis: De inhoud van het bestand is versleuteld. Totdat het is ontgrendeld met het juiste wachtwoord, zijn de gegevens onleesbaar voor elke toepassing, inclusief AI-modellen.
4. Bestandsbeschadiging of niet-standaard codering
Minder gebruikelijk, maar nog steeds een mogelijkheid, is dat het PDF-bestand zelf beschadigd is of een ongebruikelijke tekstcodering gebruikt die de parser van ChatGPT niet herkent. Dit kan gebeuren door een slechte download, een defecte bestandsconversie of bij het omgaan met zeer oude documenten. De tekstlaag kan technisch gezien bestaan, maar is op een manier versleuteld die deze ontoegankelijk maakt.
Conclusie: De belangrijkste reden waarom een speciale tool ChatGPT overtreft voor PDF-extractie, is de ingebouwde Optical Character Recognition (OCR)-engine, die specifiek is ontworpen om afbeeldingen van tekst om te zetten in machineleesbare tekens die een AI kan begrijpen.
De oplossing: Hoe je betrouwbaar tekst uit elke PDF extraheert in 3 stappen
Wanneer ChatGPT faalt, verspil dan geen tijd met het proberen van verschillende prompts of het opnieuw uploaden van hetzelfde bestand. De oplossing is om de PDF voor te bewerken met een tool die voor deze taak is gebouwd. Het gebruik van een AI-gestuurde transcriptie- en data-extractietool met een sterke OCR-engine is de meest betrouwbare weg voorwaarts.
Hier lees je hoe je dit in minder dan een minuut doet met een tool zoals Lynote AI Transcription, die gratis is voor basisgebruik en geen account vereist om te beginnen.
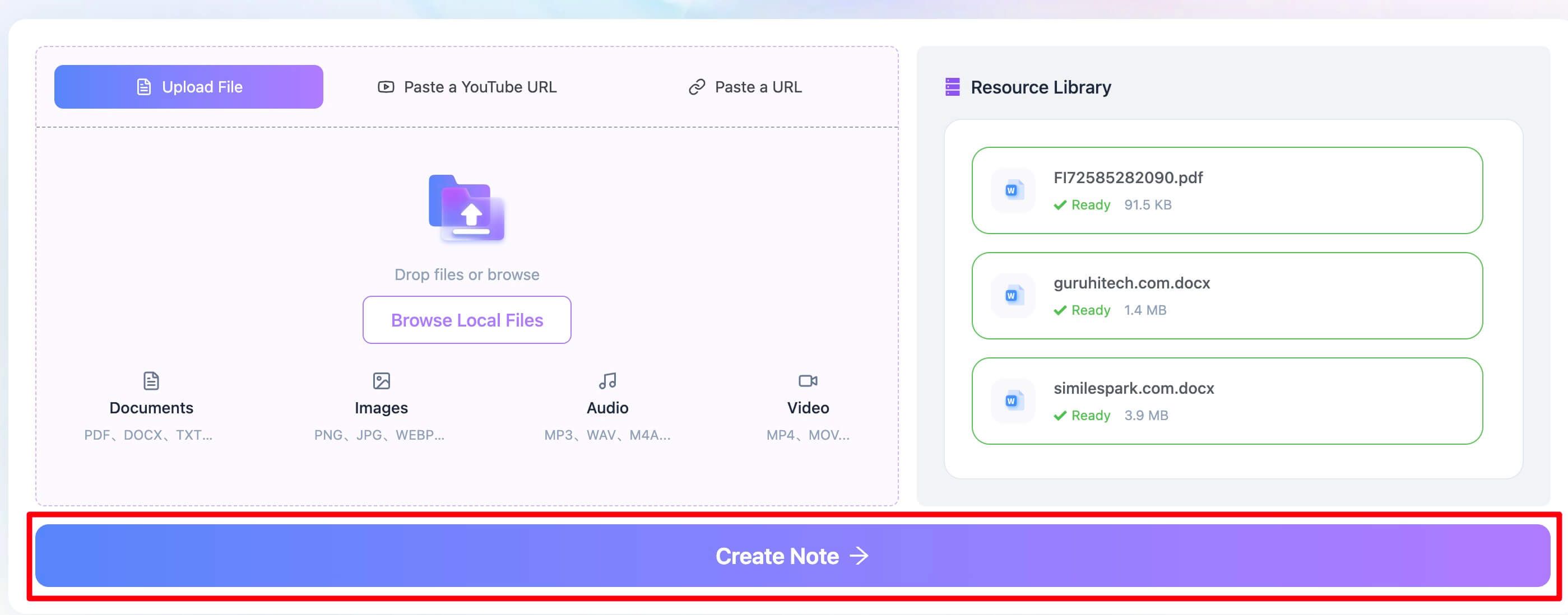
Stap 1. Upload je problematische PDF-bestand
Ga eerst naar de Lynote PDF-tekstextractor. In plaats van je bestand naar ChatGPT te uploaden, sleep je de problematische PDF rechtstreeks naar het Lynote-uploadgebied. Je kunt ook klikken om je computer te doorzoeken en het bestand te selecteren. Dit werkt perfect voor gescande collegeaantekeningen, complexe rapporten of op afbeeldingen gebaseerde documenten die ChatGPT onmiddellijk afwijst.

Stap 2. Extraheer tekst uit de PDF
Zodra je bestand is geüpload, klik je eenvoudig op de knop "Notitie maken". Dit is de cruciale stap. De backend van Lynote gaat onmiddellijk aan de slag en past een krachtige OCR-engine toe op je document. Het zoekt niet alleen naar een bestaande tekstlaag; het analyseert de pagina als een afbeelding, identificeert de tekens en reconstrueert de tekst digitaal. Het ondersteunt meer dan 130 talen, dus het is ook effectief voor internationale documenten.
Stap 3. Controleer en kopieer de PDF-tekst
Binnen enkele seconden zie je de schone, geëxtraheerde tekst verschijnen in een online editor. Nu heb je een perfecte, tekstgebaseerde bron die ChatGPT gemakkelijk kan begrijpen. Je kunt deze snel scannen op eventuele duidelijke OCR-fouten, kleine bewerkingen uitvoeren en vervolgens kopiëren om de hele tekst te pakken. Van daaruit plak je het rechtstreeks in je ChatGPT-prompt en ga je verder met je analyse, samenvatting of vraag. Je kunt de tekst ook downloaden als een .txt-bestand voor toekomstig gebruik.

Dit driestappenproces overbrugt effectief de kloof tussen je op afbeeldingen gebaseerde PDF en de tekstgebaseerde wereld van ChatGPT.

Verder dan de oplossing: Waar je op moet letten bij een PDF-tekstextractietool
Zodra je beseft dat je een speciale tool nodig hebt, zul je veel opties vinden. Dus wat onderscheidt een geweldige van een middelmatige? Hier zijn de belangrijkste functies waar je op moet letten, vooral als je regelmatig documenten verwerkt.
- OCR met hoge nauwkeurigheid: Dit is niet onderhandelbaar. De primaire taak van de tool is om afbeeldingen nauwkeurig naar tekst om te zetten. Een goede engine minimaliseert fouten (zoals het verwarren van
lmet1ofrnmetm) en verwerkt verschillende lettertypen en resoluties. - Ondersteuning voor meerdere talen: Als je werkt met internationale documenten, onderzoeksartikelen of historische teksten, zorg er dan voor dat de tool tekens en diakritische tekens kan herkennen uit de talen die je nodig hebt. Tools zoals Lynote, met ondersteuning voor meer dan 130 talen, bieden cruciale flexibiliteit.
- Batchverwerking: Probeer je tekst te extraheren uit een hele map met gescande facturen of een dozijn onderzoeksartikelen? Een tool waarmee je meerdere bestanden tegelijk kunt uploaden en deze in een wachtrij kunt verwerken, is een enorme tijdsbesparing vergeleken met het één voor één verwerken.
- Flexibele exportopties: De tekst eruit krijgen is slechts de helft van de strijd. Je moet het kunnen gebruiken. Zoek naar eenvoudige opties met één klik om te kopiëren naar klembord, te downloaden als een .txt- of .docx-bestand, of zelfs verder te integreren. Moderne tools kunnen je ook in staat stellen om direct met het document te chatten of de geëxtraheerde tekst binnen dezelfde interface te vertalen.
Het kiezen van een tool met deze functies verandert een frustrerende hindernis in een naadloos onderdeel van je onderzoeks- en analyseworkflow.
Pro-tip: Omgaan met rommelige of onnauwkeurige geëxtraheerde tekst
Zelfs de beste OCR-technologie is niet 100% van de tijd perfect, vooral niet bij scans van lage kwaliteit, handgeschreven notities of extreem complexe lay-outs. Als je geëxtraheerde tekst een beetje rommelig is, wanhoop dan niet. Hier zijn een paar professionele trucs om het snel op te schonen.
- Repareer gebroken paragrafen: Als de tekst uit kolommen is samengevoegd, zie je lange, doorlopende regels. De snelste oplossing is om de tekst in een eenvoudige editor (zoals Kladblok of TextEdit) te plakken en handmatig op "Enter" te drukken om de paragraafovergangen te herstellen. Het kost een minuut, maar maakt de tekst oneindig veel leesbaarder voor jou en voor ChatGPT.
- Gebruik Zoeken en Vervangen voor veelvoorkomende fouten: OCR's maken klassieke fouten. Als je veel
1'en ziet waarl'en zouden moeten staan, of!'en in plaats vani's, gebruik dan de functie "Zoeken en Vervangen" van je teksteditor (Ctrl+H of Cmd+Shift+H). Een paar strategische vervangingen kunnen 90% van de fouten in seconden opruimen. - Vereenvoudig voordat je samenvat: Voordat je de opgeschoonde tekst aan ChatGPT geeft voor een samenvatting, overweeg dan om irrelevante secties zoals kopteksten, voetteksten, paginanummers en bijschriftteksten te verwijderen. Dit richt de AI op de kerninhoud en leidt vaak tot een nauwkeurigere en beknoptere uitvoer.
Een beetje opschonen aan de voorkant kan je veel verwarring besparen en leiden tot veel betere resultaten van je AI-analyse.
Veelgestelde vragen
Kan ChatGPT-4o tekst lezen uit een gescande PDF?
Nee, niet direct. Zelfs de meer geavanceerde modellen zoals GPT-4o missen nog steeds een ingebouwde, gebruikersgerichte OCR-engine voor hun standaard bestandsuploadfunctie. Als je een gescande, alleen-afbeelding PDF uploadt, ontvang je dezelfde foutmelding "geen tekst kon worden geëxtraheerd". Je moet eerst een externe OCR-tool gebruiken om de PDF naar tekst te converteren en die tekst vervolgens in je prompt plakken.
Waarom werkt kopiëren en plakken wel vanuit mijn PDF, maar faalt ChatGPT?
Dit is een goede vraag die de verborgen lagen van een PDF blootlegt. Veel PDF's hebben zowel een afbeeldingslaag (wat je ziet) als een onzichtbare tekstlaag (gegenereerd toen het bestand werd gemaakt). Wanneer je markeert en kopieert, haalt je PDF-lezer (zoals Adobe Acrobat of Voorvertoning) uit die verborgen tekstlaag. Als die tekstlaag echter beschadigd, ontbreekt of slecht gecodeerd is, kan de eenvoudigere server-side parser van ChatGPT deze niet lezen, zelfs als je lokale software dat wel kan.
Is er een gratis manier om mijn PDF-tekst leesbaar te maken voor ChatGPT?
Ja. De methode die in dit artikel wordt beschreven met behulp van de gratis versie van een tool zoals Lynote is een van de meest effectieve gratis opties. Het gebruikt een hoogwaardige OCR-engine zonder dat betaling of een account nodig is voor basisextracties. Hoewel er andere gratis online OCR-tools bestaan, zitten deze vaak vol met advertenties, hebben ze een lage nauwkeurigheid of leggen ze zeer beperkende bestandsgroottelimieten op.
Waarom verdween de opmaak (vet, cursief) na extractie?
Tekstextractietools, vooral die op basis van OCR, richten zich op het vastleggen van de tekens, niet de opmaak van rich text. De uitvoer is bijna altijd platte tekst. Dit is over het algemeen beter voor AI-modellen, omdat zij zich primair bezighouden met de semantische inhoud, niet met de visuele stijl.
Conclusie: Gebruik de juiste tool voor de klus
ChatGPT is een revolutionaire tool voor het werken met taal, maar het is geen Zwitsers zakmes voor elk bestandsformaat. De foutmelding "geen tekst kon uit dit bestand worden geëxtraheerd" is geen bug; het is een grens van de mogelijkheden. Het model is gebouwd voor het verwerken van tekst, niet voor het ontcijferen van afbeeldingen van tekst die zijn opgesloten in scans of complexe lay-outs.
Voor studenten, onderzoekers en professionals die regelmatig met diverse documenten werken, is de les duidelijk: vecht niet tegen de tool, vul hem aan. Door een speciale OCR-gestuurde tekstextractor aan je workflow toe te voegen, verander je een punt van constante frustratie in een betrouwbaar tweestappenproces: extraheer eerst, analyseer dan. Deze aanpak bespaart je niet alleen tijd, maar ontsluit ook het volledige potentieel van AI voor al je documenten, niet alleen de eenvoudige.

