
ChatGPT 读不了 PDF?原因和 3 步解决方法
你手上明明是一份很重要的 PDF:可能是内容密集的学术论文、扫描版客户合同,或者教材中的某一章。你把它上传到 ChatGPT,准备让它做摘要或分析,结果却卡在这句提示上:“无法从此文件中提取文本。”
这类报错其实非常常见,而且一出现就会直接打断你的工作流程。如果你也一直被这条错误信息困住,不用怀疑自己操作错了——问题的根源在于,很多人误解了 ChatGPT 到底擅长处理什么。

核心原因很简单:ChatGPT 是语言模型,不是通用的文档转换工具。它最擅长处理的是干净、规范的数字文本。但很多 PDF,尤其是扫描件、图片版 PDF 或排版复杂的报告,本质上并不是真正的文本,而是“文字图片”。
ChatGPT 本身没有内置 OCR 文字识别能力,无法直接“读懂”这类基于图像的 PDF。你可以把它理解成:让一个非常懂语言的人去描述一本书的照片,但他看不到图片本身。本文会带你弄清楚为什么会出现这个错误,也会给你一个更稳妥的 3 步解决方案,帮你把 PDF 里的文字顺利提取出来。
快速判断:ChatGPT 还是 PDF 文字提取工具?
如果你赶时间,先看结论:到底该怎么把 PDF 转文字,关键不在 ChatGPT,而在你手里的 PDF 属于哪一类。
它是普通的文本型 PDF,还是扫描版、图片版这种难处理的文件?
下面这张表,帮你快速判断:是继续折腾 ChatGPT 的原生上传能力,还是直接换成专门做 PDF 文字识别的工具。
| 功能 / 场景 | ChatGPT(原生上传) | 专用 OCR 提取工具(如 Lynote) |
|---|---|---|
| 扫描版 / 图片版 PDF | 基本无法处理(评分:1/5) | 表现优秀(评分:5/5) |
| 多栏排版 | 效果不稳定,常出现文本错乱 | 表现较好,可尽量保留正确阅读顺序 |
| 加密或受密码保护的文件 | 无法处理(评分:1/5) | 无法处理(出于安全设计) |
| 处理速度(针对干净 PDF) | 短小、简单文件处理较快 | 速度也快,更适合大批量处理 |
| 最适合的使用场景 | 分析简单的原生文本 PDF(如从 Word 导出的文件) | 提取扫描件、文档照片或复杂排版 PDF 中的文字 |
以上评分为编辑经验判断(1=较差,5=优秀),并非实验室基准测试结果。
结论其实很明确:如果你的 PDF 是直接由 Microsoft Word 或 Google Docs 这类文本编辑器导出的,ChatGPT 也许能读出来。但只要文件经过扫描、拍照,或者排版比较复杂,就更适合用带专用 OCR 引擎的工具来做 PDF 提取文字。
ChatGPT 读不了 PDF 的 4 个主要原因
你可能会想:“我明明能在屏幕上看到这些字,为什么 ChatGPT 读不出来?”
答案就在 PDF 的结构里。PDF 并不一定像你看到的那样“就是文字”。下面这 4 个原因,正是导致“无法提取文本”报错最常见的元凶。
1. 图片版或扫描版 PDF(最常见)
这是最常见、也最容易中招的原因。你扫描纸质文件,或者把文件保存成“图片型 PDF”时,保存下来的并不是可复制的文字,而是整页内容的图像。
对电脑来说,这些字和一张树木照片里的像素没有本质区别。它看到的是图片,不是文本。
- 典型场景: 你是学生,想分析一篇 30 页的期刊论文,而这份材料是老师从图书馆纸质书里扫描出来的。你上传给 ChatGPT 后,它看到的其实只是一张张页面图片。
- 技术原因: 如果没有 OCR 文字识别,系统就无法分析图片中的字符,更别说把它们转换成机器可读取的文本。ChatGPT 需要先有可读的“文字层”,但扫描版 PDF 通常并没有这一层。
2. 排版复杂,格式不规则
PDF 很适合保留视觉排版,比如分栏、表格、页眉页脚、浮动图片等。但这种优势,恰恰也是 PDF 文字识别时的难点。ChatGPT 内置的解析能力比较基础,更适合处理线性、连续的文本内容。
- 典型场景: 你是一名商业分析师,手里有一份市场研究报告,里面包含双栏正文、图表批注和数据表格。ChatGPT 一旦开始读取,左右两栏的内容很可能被交叉拼在一起,原本通顺的句子瞬间变成乱码。
公司在第三季度的增长主要来自新的营销……表现亮眼,达到 500 万台……该策略重点投向社交媒体。 - 技术原因: 解析器分不清哪里是换栏,哪里才是段落结束。它往往按页面坐标去抓取文字,而不是按真正的逻辑顺序读取,所以最后提取出来的内容很容易前后错乱。
3. 文件被加密,或设置了密码保护
这一点相对好理解。如果 PDF 需要密码才能打开,或者限制了复制文本,ChatGPT 会遵守这些安全设置,不会也不能绕过它们。
- 典型场景: 同事发给你一份涉及敏感信息的财务报告,并设置了密码,想让你做分析。这种文件不能直接上传给 ChatGPT 指望它自动打开。
- 技术原因: 文件内容本身是加密的。只有输入正确密码后,数据才会变成可读取状态。在此之前,不管是普通软件还是 AI 模型,都无法正常读取。
4. 文件损坏,或使用了非标准编码
这种情况相对少见,但也确实会发生。PDF 文件本身可能已经损坏,或者采用了 ChatGPT 解析器无法识别的特殊文本编码。常见诱因包括下载不完整、转换过程出错,或者文件年代太久。
有时文字层在技术上“存在”,但内部编码已经乱掉了,结果就是系统虽然检测到文件里有内容,却依然无法正常提取文本。
核心结论: 专门的 PDF 提取文字工具之所以比 ChatGPT 更可靠,关键就在于它内置了 OCR 识别引擎。 这类引擎专门用于把图片中的文字转换成机器可读字符,后续 AI 才能继续理解、总结和分析。
3 步搞定:稳定提取任意 PDF 中的文字
如果 ChatGPT 提取失败,别再反复换提示词,也别一遍遍重新上传同一个文件。更快的办法,是先用专门做 PDF 提取文字 的工具把文件预处理好。对于扫描版 PDF、图片版 PDF 或排版复杂的文件,带强大 OCR 识别能力的转写与数据提取工具,通常才是更稳妥的解决方案。
下面教你怎么在 1 分钟内搞定。你可以用 Lynote AI 转写 这类工具:基础功能可免费使用,开始前也不用注册账号。
第 1 步:上传有问题的 PDF 文件
先打开 Lynote 的 PDF 文字提取工具。不要把文件上传到 ChatGPT,直接把无法识别的 PDF 拖到 Lynote 的上传区域即可。你也可以点击选择,从电脑里找到对应文件上传。像扫描版讲义、复杂报告、图片版文档这类 ChatGPT 经常直接拒绝处理的文件,都很适合用这种方式。

第 2 步:提取 PDF 文字
文件上传完成后,直接点击 “Create Note” 按钮。这一步最关键。Lynote 会立即在后台处理文档,调用高精度 OCR 引擎进行 PDF 文字识别。它不只是查找文件里是否已有文本层,还会把整页当作图片来分析,识别其中的字符,再重建成可编辑、可读取的数字文本。它支持 130 多种语言,因此处理多语种文档也同样有效。
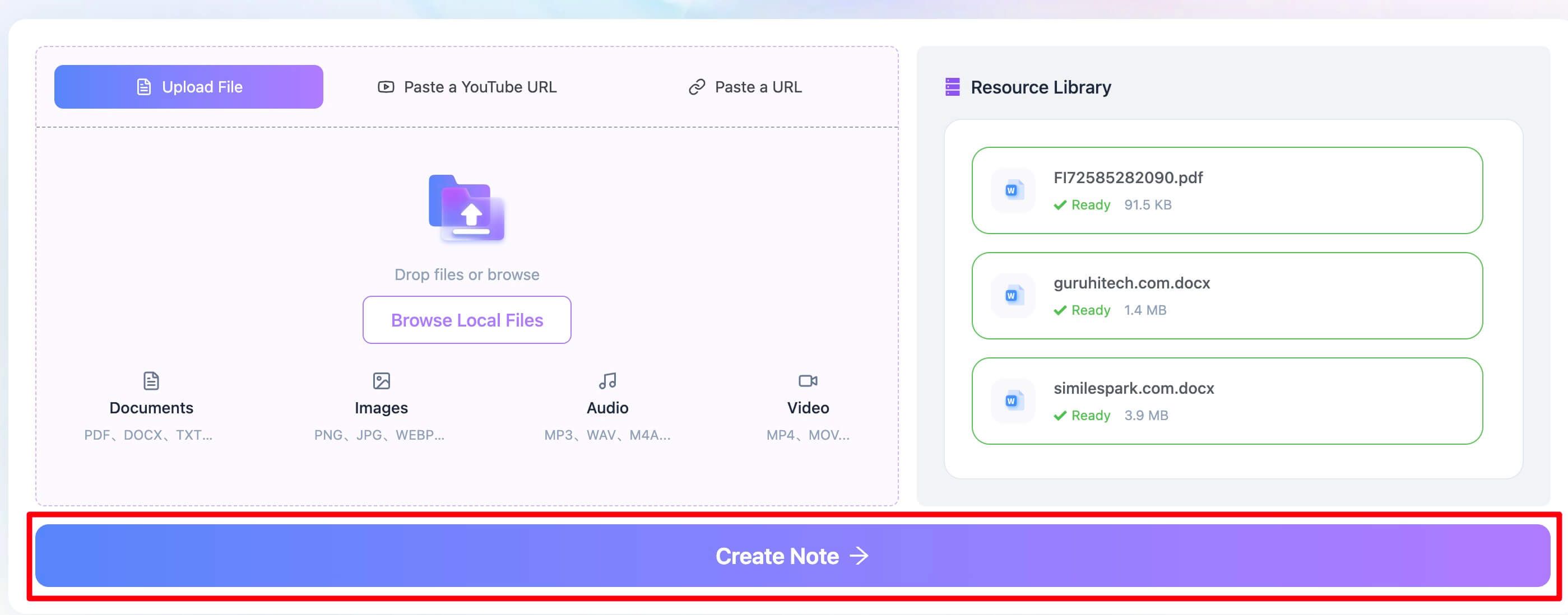
第 3 步:检查并复制提取出的 PDF 文本
几秒钟后,你就能在在线编辑器里看到已经提取好的干净文本。这样一来,你就有了一份 ChatGPT 更容易理解的纯文本内容。你可以先快速检查一下是否有明显的 OCR 识别错误,顺手做些小修改,然后一键复制全部文本。接着把内容直接粘贴到 ChatGPT 的提示词里,继续做总结、分析或提问。你也可以把文本下载为 .txt 文件,方便后续使用。

这 3 个步骤,基本就能把图片版 PDF 和 ChatGPT 之间的“无法读取”问题顺利打通。

不只是修复问题:PDF 文字提取工具该看哪些功能
当你意识到需要专门的工具后,会发现市面上选择很多。那么,好用和不好用的差别到底在哪?如果你经常处理文档,下面这些功能尤其值得重点看。
- 高准确率 OCR: 这是最核心的能力,不能妥协。工具最重要的任务,就是把图片里的文字尽可能准确地转成文本。好的 OCR 引擎能明显减少识别错误,比如把
l识别成1,或把rn识别成m,同时也能适应不同字体和分辨率。 - 多语言支持: 如果你经常处理外文资料、论文或历史文献,要确认工具能识别你需要的语言字符和重音符号。像 Lynote 这样支持 130+ 语言的工具,在实际使用中会灵活很多。
- 批量处理: 如果你要从整文件夹的扫描发票,或十几篇论文里批量提取文字,支持一次上传多个文件并排队处理的工具,会比逐个操作省下大量时间。
- 灵活的导出方式: 能提取出来只是第一步,关键还得方便后续使用。建议优先选择支持一键 复制到剪贴板、下载为 .txt 或 .docx 文件,甚至还能继续联动处理的工具。现在一些更完善的工具,还支持在同一界面里直接 和文档对话,或对提取后的文本继续翻译。
选对具备这些功能的工具,原本卡住流程的问题,往往就能变成你研究和分析工作中的顺畅一环。
实用技巧:提取出来的文字很乱或不准怎么办
即使是很强的 OCR 技术,也做不到 100% 完美,尤其遇到低质量扫描件、手写笔记或排版特别复杂的页面时更是如此。如果你发现提取出来的文本有点乱,也不用着急。下面几个实用方法,通常能帮你很快整理干净。
- 修复断掉或错乱的段落: 如果多栏排版的内容被合并到一起,文本里通常会出现很长、很乱的一整行。最快的处理方式,是先把文字粘贴到简单编辑器里(比如记事本或 TextEdit),再手动按 “Enter” 重新分段。虽然只多花 1 分钟,但可读性会大幅提升,ChatGPT 也更容易理解。
- 用查找替换处理常见识别错误: OCR 常有一些典型误差。如果你发现很多
1本该是l,或者!被误识别成i,就可以直接用文本编辑器里的“查找和替换”功能(Ctrl+H 或 Cmd+Shift+H)。做几次有针对性的替换,往往几秒钟就能修正大部分错误。 - 先精简,再让 ChatGPT 总结: 在把清理后的文本交给 ChatGPT 做总结前,可以先删掉页眉、页脚、页码、图片说明等无关内容。这样能让 AI 更聚焦在正文核心信息上,输出通常也会更准确、更简洁。
前面多花一点时间清理文本,往往能帮你少走很多弯路,也能让后续的 AI 分析结果明显更好。
常见问题
ChatGPT-4o 能读取扫描版 PDF 里的文字吗?
不能直接读取。即使是 GPT-4o 这类更先进的模型,在标准文件上传功能里,依然没有面向用户开放的内置 OCR 引擎。如果你上传的是扫描版 PDF 或纯图片 PDF,通常还是会看到“无法提取文本”之类的报错。正确做法是先用外部 OCR 工具把 PDF 转文字,再把文本粘贴进提示词中。
为什么我的 PDF 可以复制文字,但 ChatGPT 却读不了?
这个问题很典型,也正好说明 PDF 其实有“隐藏层”。很多 PDF 同时包含图像层(你看到的内容)和不可见的文本层(文件生成时附带的文字信息)。当你选中文字并复制时,PDF 阅读器(比如 Adobe Acrobat 或 Preview)读取的其实是这层隐藏文本。但如果这层文本已经损坏、缺失,或者编码不规范,ChatGPT 在服务器端使用的较简单解析器就可能无法正确读取,即使你本地软件还能复制。
有没有免费的方法让 ChatGPT 读懂 PDF 文字?
有。本文介绍的这种方法,比如使用 Lynote 的免费版本,就是目前比较有效的免费方案之一。它在基础 PDF 提取文字 场景下,不需要付费,也不用注册账号,就能调用高质量 OCR 引擎完成识别。虽然网上也有其他免费的 PDF OCR 识别工具,但很多广告很多、识别准确率不高,或者对文件大小限制非常严格。
为什么提取后加粗、斜体等格式都没了?
文字提取工具,尤其是基于 OCR 的工具,核心目标是识别并提取_文字内容_,而不是保留加粗、斜体这类富文本格式。所以导出的结果通常都是纯文本。对 AI 模型来说,这反而更实用,因为它更关注语义内容,而不是视觉样式。
结论:用对工具,处理更省事
ChatGPT 在语言处理上确实很强,但它并不是适合所有文件格式的万能工具。出现“无法从此文件中提取文本”这类提示,并不一定是出错了,更常见的是能力边界所致。它擅长处理干净、可读取的文本,却不擅长直接识别扫描件、图片版 PDF,或排版复杂文件里“藏着”的文字内容。
如果你经常要处理各种文档,不管是学生、研究人员还是职场用户,结论都很明确:别硬让 ChatGPT 做它不擅长的事,正确做法是搭配专门的工具。 在工作流里加上一个支持 OCR 的 PDF 文字提取工具后,原本反复踩坑的问题就能变成稳定的两步:先提取文字,再交给 AI 总结或分析。这样不仅更省时间,也能让 AI 真正处理更多类型的文档,而不只是那些结构简单、文本干净的 PDF。

